Quantitative Lexikologie
Die Quantitative Lexikologie erforscht den Wortschatz (die Lexik) beliebiger Sprachen im Hinblick auf Struktur und Veränderungen mit dem Ziel, die Gesetzmäßigkeiten aufzudecken, die am Zustandekommen des Zustandes beteiligt sind, in dem sich ein bestimmter Wortschatz zu einem bestimmten Zeitpunkt befindet. Oberstes Ziel ist es, eine Theorie der Lexik zu entwickeln, die aus Sprachgesetzen besteht, die miteinander in wechselseitiger Beziehung stehen und es erlauben, beobachtete Zustände und Prozesse auf wissenschaftliche Weise zu erklären. Insofern ist die Quantitative Lexikologie eine wichtige Teildisziplin der Quantitativen Linguistik.
Einige Aspekte der quantitativen Lexikologie
Eine bahnbrechende Untersuchung hat Köhler (1986) vorgelegt. Er entwickelt in dieser Arbeit durch Analyse eines Korpus von rund 13000 Lemmata[1] in Grundzügen die Linguistische Synergetik, deren wesentliche Zielsetzung darin besteht, das Zusammenwirken von Sprachgesetzen zu erarbeiten. Ein Beispiel: Die Länge eines Lexems wird von seiner Häufigkeit (Frequenz) und der Größe des Lexikons der betreffenden Sprache beeinflusst und sie steuert ihrerseits die Zahl der Bedeutungen des entsprechenden Lexems.[2] Was Köhler anhand eines deutschen Korpus erarbeitet hat, konnte anhand des Polnischen[3] und Japanischen[4] bestätigt werden. Dieser Ansatz zeigt auf, wie man aus der Sicht der Quantitativen Linguistik und damit auch der Quantitativen Lexikologie zu einer Sprachtheorie kommen kann.
Als weitere Themen kann man nennen: die phonologische und morphologische Struktur der Wörter, die Bedeutung der Wörter, ihre dialektale Verbreitung sowie Prozesse des Wachstums und Verlustes des Wortschatzes.[5]
Ein Beispiel
Als ein Beispiel für die Gesetzmäßigkeiten, die die Struktur des Wortschatzes steuern, kann man die Wortlänge betrachten. Untersucht man die Abhängigkeit der mittleren Wortlänge von der Häufigkeit der Wörter, so lässt sich nachweisen, dass dieser Zusammenhang für eine Stichprobe aus einem deutschen Häufigkeitswörterbuch mit angemessen dargestellt werden kann. Dies gilt sowohl dann, wenn die Wortlängen durch die Zahl der Phoneme, als auch dann, wenn als Kriterium die Zahl der Silben pro Wort bestimmt wird. Wählt man stattdessen die Zahl der Morphe pro Wort, muss der genannten Formel noch ein weiterer Faktor hinzugefügt werden.

Gegenstand einer solchen Untersuchung[6] waren die häufigsten 8000 Wörter eines Häufigkeitswörterbuchs des Deutschen, wobei für die häufigsten 1000 (x = 1), dann für die zweithäufigsten 1000 Wörter (x = 2) undsoweiter anhand einer Stichprobe jeweils die Mittelwerte der Wortlängen bestimmt wurden. Als Beispiel das Ergebnis für den Teil der Untersuchung, bei dem die Wortlänge nach der Zahl der Silben bestimmt wurde:
| x | n(x) | NP(x) |
|---|---|---|
| 1 | 1.95 | 1.92 |
| 2 | 2.10 | 2.23 |
| 3 | 2.55 | 2.41 |
| 4 | 2.55 | 2.53 |
| 5 | 2.60 | 2.62 |
| 6 | 2.50 | 2.68 |
| 7 | 2.90 | 2.72 |
| 8 | 2.70 | 2.75 |
Dabei steht x für das erste, zweite, dritte bis achte Tausend der Wörter; n(x) die beobachtete durchschnittliche Wortlänge (in Silben) des entsprechenden Tausends, NP(x) die berechnete Wortlänge, die man erhält, wenn man die angegebene Formel an die Beobachtungswerte anpasst. a, b und c sind die Parameter der angegebenen Formel. Das dargestellte Ergebnis ist mit einem Determinationskoeffizienten D = 0,85 signifikant. D muss größer/gleich 0,80 sein, um ein signifikantes Ergebnis anzuzeigen; diese Bedingung ist erfüllt. Zumindest für diese Stichprobe ist klar, dass entsprechend der Hypothese die Frequenz die Wortlänge beeinflusst: Je häufiger Wörter sind, desto kürzer sind sie im Durchschnitt.
Verteilung verschiedener Formen oder Funktionen
In vielen Fällen ist schon die Erhebung der Häufigkeit erhellend, mit der verschiedene Formen oder Funktionen von Lexemen zu beobachten sind.
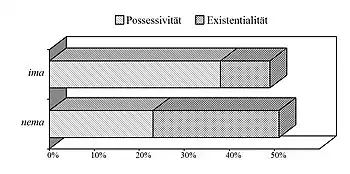
Ein Beispiel: Wenn man nicht nur alle Existentialsätze, sondern auch alle Possessivsätze mit habere aus dem Korpus der serbokroatischen Sprache einbezieht, dann tritt die affirmative Form ima (es gibt) fast genauso häufig in Erscheinung wie die negierte Form nema. Bei der affirmativen Form ima ist durchschnittlich jeder fünfte Gebrauch existential, bei der negierten Form nema jedoch jeder zweite (s. Diagramm). Das bedeutet, dass annähernd drei Viertel des existentialen Gebrauchs von habere im Korpus in negierter Form realisiert sind.[7]
Literatur
- Gabriel Altmann, Dariusch Bagheri, Hans Goebl, Reinhard Köhler, Claudia Prün: Einführung in die quantitative Lexikologie. Peust & Gutschmidt, Göttingen 2002, ISBN 3-933043-09-3, S. 94–133.
- Rolf Hammerl: Untersuchungen zur Struktur der Lexik: Aufbau eines lexikalischen Basismodells. Wissenschaftlicher Verlag Trier, Trier 1991, ISBN 3-88476-005-X.
- Volodymir Kaliuščenko, Reinhard Köhler, Viktor Levickij (Hrsg.): Problemy typolohičnoi ta kvantytatyvnoi leksikologii – Problems of Typological and Quantitative Lexicology. Ruta, Černivci 2007, ISBN 978-966-568-897-6. (Beiträge in Deutsch, Englisch, Russisch und Ukrainisch)
- Reinhard Köhler: Zur linguistischen Synergetik: Struktur und Dynamik der Lexik. Brockmeyer, Bochum 1986, ISBN 3-88339-538-2.
- Reinhard Köhler: Properties of lexical units and systems. In: Reinhard Köhler, Gabriel Altmann, Gabriel, Rajmund G. Piotrowski (Hrsg.): Quantitative Linguistik – Quantitative Linguistics. Ein internationales Handbuch. de Gruyter, Berlin/ New York 2005, ISBN 3-11-015578-8, S. 305–312.
- Juhan Tuldava: Probleme und Methoden der quantitativ-systemischen Lexikologie. Wissenschaftlicher Verlag Trier, Trier 1998, ISBN 3-88476-314-8.
Weblinks
Einzelnachweise
- Es handelt sich um einen Auszug aus dem sogenannten LIMAS-Korpus; R. Köhler: Zur linguistischen Synergetik. 1986, S. 95.
- R. Köhler: Zur linguistischen Synergetik. 1986, S. 74.
- R. Hammerl: Untersuchungen zur Struktur der Lexik. 1991.
- Haruko Sanada: Investigations in Japanese Historical Lexicology. überarb. Auflage. Peust & Gutschmidt, Göttingen 2008, ISBN 978-3-933043-12-2, besonders S. 113–141.
- G. Altmann, D. Bagheri und andere: Einführung in die quantitative Lexikologie. 2002.
- Karl-Heinz Best: Frequenz und Länge von Wörtern. In: V. Kaliuščenko und andere: Problemy typolohičnoi ta kvantytatyvnoi leksikologii. 2007, S. 83–90, Tabelle S. 87.
- Snježana Kordić: Wörter im Grenzbereich von Lexikon und Grammatik im Serbokroatischen (= Lincom Studies in Slavic Linguistics. Band 18). Lincom Europa, München 2001, ISBN 3-89586-954-6, S. 206.