Parallele Breitensuche
Die parallele Breitensuche (englisch parallel breadth-first search (BFS)) ist in der Informatik eine Variante des Breitensuche-Algorithmus für Graphen, bei der dieser Algorithmus nebenläufig auf mehreren Prozessoren verteilt (parallelisiert) ausgeführt wird.
Bei der Breitensuche werden ausgehend von einem Ausgangsknoten alle von diesem erreichbaren Knoten besucht, wobei sichergestellt wird, dass Knoten mit einer geringeren Distanz zum Ausgangsknoten vor anderen Knoten mit einer höheren Distanz besucht werden.
Allgemeines
Die parallele Breitensuche ist Grundlage für viele andere Algorithmen und wird dabei insbesondere bei der Analyse von großen Datenbeständen genutzt. Mit Hilfe der Breitensuche lassen sich z. B. der maximale Fluss, Zusammenhangskomponenten oder das Zentralitätsmaß in Graphen bestimmen. Der Algorithmus kommt außerdem beim Graph500-Benchmark zum Einsatz, um die Leistung von Supercomputern bei der Verarbeitung von großen Datenmengen zu vergleichen. Eine ähnliche Variante dieses Benchmarks ist der Green500, bei dem die Leistung im Verhältnis zum Stromverbrauch verglichen wird.[1]
Speichermodelle
Eine wichtige Rolle bei der Betrachtung von parallelen Algorithmen spielen das zugrundeliegende Speichermodell und die Kommunikation zwischen den einzelnen Prozessen. Grundsätzlich unterscheidet man hierbei zwischen zwei verschiedenen Speichermodellen:
- Beim gemeinsamen Speicher (Shared Memory) kann jeder Prozessor auf denselben geteilten Hauptspeicher zugreifen
- Bei verteiltem Speicher (Distributed Memory) besitzt jeder Prozessor einen eigenen, von den restlichen Prozessoren getrennten, lokalen Speicher. Die Prozessoren müssen bei diesem Modell Nachrichten austauschen, um Daten zu teilen.
Level-basierter Algorithmus

| Animiertes Beispiel des Level-basierten Algorithmus |
Die Breitensuche wird im sequenziellen Betrieb in der Regel mit einer FIFO-Queue umgesetzt (siehe Breitensuche). Eine mögliche Umsetzung des Algorithmus kann folgendermaßen beschrieben werden:
- Markiere alle Knoten als nicht besucht
- Wähle einen Startknoten und füge ihn in die aktuelle Warteliste und markiere als besucht
- Wiederhole, solang nicht leer ist
- Entferne den ersten Knoten aus
- Füge alle mit verbundenen Knoten, die noch nicht besucht wurden, in die neue Warteliste und markiere sie als besucht
- Falls nicht leer ist, tausche und und gehe zu Schritt 3




Bei dem Algorithmus gilt die folgende Schleifeninvariante: Bei der -ten Durchführung von Schritt 3 befinden sich alle Knoten mit der Distanz vom Startknoten aus in (aktuelles Level). In Schritt 4 befinden sich alle Knoten mit der Distanz in der Liste (nächstes Level). Da dieser Algorithmus von der Knotenmenge des aktuellen Levels ausgehend nach weiteren Knoten sucht, wird er auch als Top-down-Algorithmus bezeichnet. Ist die Menge der Knoten im aktuellen Level sehr groß, so bietet sich auch eine Bottom-up-Variante an. Bei dieser Methode werden alle bisher noch nicht besuchten Knoten ausgesucht. Diese beiden Varianten können auch als Hybrid-Algorithmus gemeinsam verwendet werden.[2]


Um den dargestellten Algorithmus parallel auszuführen, kann die Schleife in mehrere Prozesse aufgeteilt werden. Dazu muss sichergestellt werden, dass der Zustand der Warteliste und die Datenstruktur, in welcher der Zustand der Knoten (bereits besucht oder nicht) gespeichert ist, zwischen den Prozessoren synchronisiert wird.[1] Ohne weitere Anpassung ist dieser Algorithmus nur im Shared-Memory-Modell möglich.
BFS mit Partitionierung
Eine Möglichkeit, den Algorithmus in mehrere Prozesse mit verteiltem Speicher aufzuteilen, besteht darin, jedem Prozess einen eigenen Teil der Knoten des Graphen zuzuordnen. Dieses Verfahren bezeichnet man als Partitionierung.
1D-Partitionierung
Im einfachsten Fall werden jedem der Prozesse Knoten mit allen ausgehenden Kanten zugeordnet, wobei die Anzahl der Knoten und die Anzahl der Prozesse bezeichnet. In diesem Fall hält jeder Prozessor den Zustand der ihm zugewiesenen Knoten im eignen Speicher. Durch die Partitionierung muss nach jedem Schritt zwischen den Prozessoren kommuniziert werden, da die ausgehenden Kanten nicht unbedingt auf Knoten zeigen, die demselben Prozessor zugeordnet sind. Da potenziell jeder Prozessor jedem anderen eine Nachricht senden muss, muss hier die All-to-all-Kommunikation verwendet werden.[3]



2D-Partitionierung
In vielen Fällen besitzt der Graph nur sehr wenige Kanten im Vergleich zur Anzahl der Knoten. Stellt man den Graphen mit Hilfe einer Adjazenzmatrix dar, erhält man eine sehr dünn besetzte Matrix. Stellt man nun die Knoten, die im aktuellen Level besucht wurden, als Vektor dar, lässt sich der nächste Schritt der Breitensuche durch eine Multiplikation des Vektors mit der Adjazenzmatrix darstellen. Die Multiplikation eines dünnbesetzten Vektors mit einer dünnbesetzten Matrix (Sparse Matrix Vector Multiplication (SpMV)) lässt sich effizient umsetzen.
Die Adjazenzmatrix lässt sich in mehrere Untermatrizen einteilen. Jede Untermatrix entspricht dabei einem Teil der Kanten im Graphen. Die Breitensuche lässt sich dadurch parallelisieren, dass jeder Prozessor einen eigenen Teil der Adjazenzmatrix bearbeitet.[3]
Funktionsweise anhand eines Beispiels
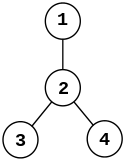 |
|
| Graph |
die dazugehörige Adjazenzmatrix |
|---|



- Wir wählen die Anzahl der Spalten, in die wir unsere Matrix aufteilen möchten, mit und die Anzahl der Zeilen mit . Da unsere Adjazenzmatrix eine -Matrix ist, haben unsere Untermatrizen jeweils 2 Zeilen und Spalten. Die bei der Partitionierung erhaltenen Untermatrizen, die jeweils einem Prozessor zugeordnet werden, sehen wie folgt aus:




- Im Folgenden wird nun ein einziger Berechnungsschritt der Breitensuche für den Prozessor, der die Matrix besitzt, betrachtet:

- Der Prozessor berechnet den Teil der Breitensuche, der durch die in enthaltenen Kanten gegeben ist. In ist dies die Kante zwischen Knoten 1 und 2. Für die Berechnung der Breitensuche benötigt zunächst als Eingabe den Vektor mit zwei Elementen, der angibt, ob Knoten 1 und 2 im letzten Schritt der Breitensuche besucht wurden.
- Um einen aktuellen Zustand des Vektors zu erhalten, muss mit allen Prozessoren in der gleichen Spalten kommunizieren, da jeder dieser Prozessoren einen der beiden Knoten im letzten Schritt besucht haben könnte. In diesem Beispiel muss der Vektor also nur mit ausgetauscht werden.
- Anschließend wird der Vektor mit multipliziert, um die Knoten zu erhalten, die im nächsten Schritt erreicht werden. Sei (d. h., Knoten 1 wurde im vorherigen Schritt besucht), gilt , wobei die Eins in der zweiten Komponente darauf hinweist, dass im nächsten Schritt Knoten 2 besucht wird.
- Das Ergebnis der Matrix-Vektor-Multiplikation muss nun mit allen Prozessoren in der gleichen Zeile ausgetauscht werden. Durch diesen Kommunikationsschritt wird der besucht-Zustand der Knoten abgeglichen und werden mögliche Konflikte für den Fall gelöst, dass mehrere Prozessoren denselben Knoten besuchen. Anschließend beginnt der Prozess wieder von vorn.




Der Vorteil gegenüber der 1D-Partitionierung besteht darin, dass jeder Prozessor nur mit den Prozessoren in derselben Reihe und Spalte kommunizieren muss, nicht jedoch mit allen anderen Prozessoren. Im Vergleich zur 1D-Partitionierung sind dafür jedoch zwei anstatt ein einziger Kommunikationsschritt für jede Ebene notwendig.
Weblinks
- Beispiel-Implementierung in C++ mit Atomics
Einzelnachweise
- Yasui Y., Fujisawa K. (2017) Fast, Scalable, and Energy-Efficient Parallel Breadth-First Search. In: Anderssen B. et al. (eds) The Role and Importance of Mathematics in Innovation. Mathematics for Industry, vol 25. Springer, Singapore
- Ueno, K., Suzumura, T., Maruyama, N. et al. Data Sci. Eng. (2017) 2: 22. doi:10.1007/s41019-016-0024-y
- Aydin Buluç and Kamesh Madduri. 2011. Parallel breadth-first search on distributed memory systems. In Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis (SC '11). ACM, New York, NY, USA, Article 65, 12 pages. doi:10.1145/2063384.2063471