Parallel Quicksort
Parallel Quicksort beschreibt Parallelisierungen des sequentiellen Algorithmus Quicksort, welcher auf dem Teile-und-Herrsche-Prinzip basiert.
Wie Quicksort teilt Parallel Quicksort eine Menge von Elementen mithilfe eines Pivotelements in zwei Teilmengen auf, sodass die Elemente in der einen Teilmenge kleiner als das Pivot sind und die Elemente in der anderen Teilmenge größer oder gleich dem Pivot sind. Danach werden die neuen Mengen wieder jeweils in Teilmengen unterteilt.
Dieses Vorgehen kann auf verschiedene Arten parallel implementiert werden. Zum einen können mehrere Mengen von jeweils einem Prozess in neue Teilmengen aufgeteilt werden[1]. Dies hat den Nachteil, dass der erste Rekursionslevel nicht parallelisiert ist und der Speedup gegenüber Quicksort auf begrenzt ist. Zum anderen können mehrere Prozesse zusammen arbeiten und gemeinsam eine einzelne Menge aufteilen. Dieser Ansatz hat sich in der Praxis als effizienter erwiesen. Parallel Quicksort kann im PRAM Modell mit einer Laufzeit von implementiert werden[2].


Naiver Ansatz
Arbeitsweise
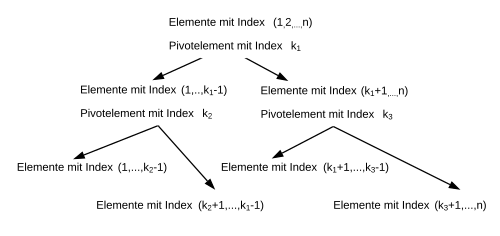






Bei jedem rekursiven Aufruf von Quicksort wird die Menge der Elemente wiederholt in zwei aufgeteilt. Die erste Partitionierung kann nur von einem einzigen Prozessor durchgeführt werden. Alle weiter erzeugte Untermengen des Arrays, die auf der gleichen Stufe der Rekursion sind, können von zwei weitere Prozessoren parallel ohne Speicherkonflikte verarbeitet werden[1]. Die Zuweisung von den Untermengen an den verschiedenen Prozessoren hat einen zusätzlichen Overhead. Wenn die zwei Mengen klein genug sind oder weniger Prozessoren zur Verfügung stehen, ist es manchmal effizienter einen sequenziellen Sortieralgorithmus anzuwenden, anstatt einen neuen rekursiven Aufruf von Quicksort zu machen.
Es ist dabei möglich, dass manche Prozessoren schneller mit der Partitionierung seiner Untermenge fertig sind, im Vergleich zu anderen. Eine Warteschlange kann dazu benutzt werden, wo die Zeiger auf noch nicht partitionierte Untermengen gespeichert werden. Bei der Entfernung von der Warteschlange sind die größeren Untermengen bevorzugt, da diese neue kleinere Untermengen erzeugen, die wiederum in die Warteschlange kommen. Das Ziel dabei ist, möglichst viele Untermengen zu haben, und dabei die Prozessoren dauerhaft besetzt zu halten.
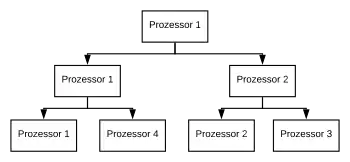
Allokation von Prozessoren
Die Reihenfolge bei der Allokation von Prozessoren an Untermengen wird dynamisch angepasst. Prozessor 1 partitioniert die Menge der Elemente mit Index . Die erste entstandene Untermenge, , verarbeitet wieder Prozessor 1 und die zweite, , Prozessor 2. Die Menge der Elemente ist o. B. d. A. die kleinere von beiden. Daher ist es plausibler, dass diese von Prozessor 2 schneller partitioniert wird. Prozessor 2 fordert also früher als Prozessor 1 für seine Untermengen einen neuen Prozessor an. Infolgedessen verarbeitet Prozessor 2 die eine erhaltene Untermenge, während Prozessor 3 die andere. Wenn Prozessor 1 einen neuen Prozessor anfordert, bekommt er Prozessor 4, weil dieser zurzeit frei ist.
Das folgende Pseudocode skizziert eine Implementierung von Parallel Quicksort. bezeichnet die maximale Größe des Array, welcher effizienter mit einem sequentiellen Sortieralgorithmus, z. B. Insertionsort, zu sortieren ist.

PROCEDURE QUICKSORT (L,U);
IF U-L > M THEN;
BEGIN
PARTITION (L,U)
FORK L1, L2
L1: QUICKSORT (L,K-1)
GOTO L3
L2: QUICKSORT (K+1,U)
GOTO L3
L3: JOIN L1, L2
END
ELSE IF U-L > 1 THEN INSERTION_SORT (L,U)
Laufzeit
Dieser Ansatz erreicht eine niedrigere Beschleunigung gegenüber dem sequentiellen Quicksort[3].
Um eine -elementige Menge mit einem Pivotelement aus der gleichen Menge zu partitionieren, braucht man Vergleiche. Es sei angenommen, dass ein Vergleich eine Zeiteinheit braucht. Weiterhin, sei die ursprüngliche Größe des Arrays , die Anzahl an Prozessoren mit und das ausgewählte Pivotelement immer der wahre Median von der zu partitionierenden Untermenge.




Unter diesen Annahmen kann die Anzahl der Vergleiche des sequentiellen Algorithmus durch die folgende Rekurrenzrelation bestimmt werden:

mit Lösung:

Die Laufzeit von Parallel Quicksort kann als die Summe der Laufzeiten von zwei Abschnitten bestimmt werden.
In dem ersten Abschnitt gibt es mindestens so viele Prozessoren wie Untermengen, die zu partitionieren sind. Für die erste Partitionierung wird von alle Prozessoren, die zur Verfügung stehen, nur einen genutzt. Die weiteren Prozessoren bleiben inaktiv. Diese Iteration braucht Zeiteinheiten, um Vergleiche durchzuführen. Bei der zweiten Partitionierung sind nur zwei Prozessoren aktiv und warten. Wenn , werden Zeiteinheiten für Vergleiche benötigt. Die dritte Partitionierung braucht analog bei mindestens Zeiteinheiten für Vergleiche. Bei der ersten Iteration gibt es genug Prozessoren für jede Partition. Die Laufzeit für diesen Zeitabschnitt kann durch die folgende Formel ausgedrückt werden:











Die Anzahl der Vergleiche beträgt:

In dem zweiten Abschnitt gibt es mehr Untermengen als Prozessoren verfügbar. Wenn es angenommen wird, dass jeder Prozessor gleichviele Vergleiche durchführt, ist die Laufzeit die Anzahl der Vergleiche dividiert durch . Daher folgt:


Die erwartete Beschleunigung beträgt:
.

Die beste Beschleunigung bei z. B. und ist ca. , welche niedrig ist. Das Problem ist, dass am Anfang nur wenige Prozessoren aktiv sind und es eine Menge Zeit dauert, bis alle Prozessoren Arbeit bekommen.



Parallelisierung von Quicksort auf EREW PRAM
Im Jahr 1991, stellen Zhang und Nageswara eine Möglichkeit für die Parallelisierung von Quicksort auf einer EREW PRAM vor[2]. Der Algorithmus sortiert Elemente mit Prozessoren in erwartete Laufzeit und in deterministische Laufzeit mit an Speicherbedarf. In dem Fall, dass ist, dann sind die Kosten optimal in Bezug auf das Produkt von der Zeit und Anzahl von Prozessoren.



Arbeitsweise
Der Algorithmus wird in drei Schritten ausgeführt. Erstens wird die ursprüngliche Menge von Elementen in Blöcken aufgeteilt, sodass jeder Block Elemente hat, außer der letzte, welcher weniger als Elemente haben kann. Jedem Prozessor wird einen Block zugewiesen, d. h. Prozessor verarbeitet Block . Ein Pivotelement wird auswählt und jedem Prozessor mit einem Parallel Broadcasting herausgeschickt.




In dem zweiten Schritt markiert jeder Prozessor alle Elemente aus seinem Block mit entweder 0 oder 1, abhängig davon, ob das Element kleiner oder größer als das Pivotelement ist. Mit einem parallelen Präfix Algorithmus kann der Rank von jedem Element innerhalb der Gruppe 0 bzw. Gruppe 1 berechnet werden. Die Idee ist, alle Elemente aus allen Blöcken, die mit "0" markiert wurden, vor alle "1"-Elemente aller Blöcken in einem weiteren Array zu speichern. Das Index vom Element in wird anhand seines Ranks und der Nummer seines Blocks berechnet. So hat man alle Elemente aus der ursprünglichen Menge in zwei Teile aufgeteilt – die Menge mit allen "0"-Elementen und mit allen "1"-Elementen.



Der dritte Schritt besteht aus der Überprüfung der Länge von und und wenn diese mehr als ein Element enthalten, folgt ein rekursiver Aufruf von Schritt eins auf beide.
Wahl des Pivotelements und Laufzeitberechnung
Nur ein zusätzliches Array mit Länge und konstanten Bedarf an weiteren Hilfsvariablen werden benötigt. Bei dem Rekursionsaufruf kann das ursprüngliche Array wiederverwendet werden und beim nächsten Aufruf andersrum. Daher bleibt der zusätzliche Speicherbedarf in .

Die Laufzeit von dem Algorithmus hängt von der Wahl des Pivotelements. Eine Möglichkeit ist, ein zufälliges Element als Pivot zu nehmen.
Annehmend, kann ein Prozessor eine zufällige ganze Zahl von dem Bereich in konstante Zeit generieren, dann entspricht die Partitionierung mit Pivotelement – das Element mit Index , einem Random Binary Search. Die Analyse[4] besagt, dass für die Höhe, , von einem Random-Binary-Search-Tree mit Elementen, gilt . Daher liegt die Tiefe der Rekursion bei . Das Pivotelement muss zusätzlich noch verschickt werden. Dies erfolgt in [5]. Jeder Prozessor muss dann die Elemente in seinem Block markieren, die Präfix Summe muss berechnet werden[6] und die Elemente verschoben werden. Dies braucht gesamt . Anschließend berechnet man die Gesamtlaufzeit für diesen Fall, diese ist erwartet.






In dem Fall, dass das Pivotelement nicht zufällig gewählt wurde, hängt die Laufzeit des Algorithmus von der Rekursionstiefe und damit auch von dem Verhältnis der Größen und ab. Die Rekursionstiefe vom Algorithmus kann auf begrenzt werden, wenn und ungefähr gleich sind. Dies kann gewährleistet werden, indem die Auswahl des Pivotelements mit dem Parallel Median Finding Algorithm von Akl auf eine EREW PRAM in Zeit[7] erfolgt. Das Markieren, die Präfix Summe und das Verschieben der Elemente erfolgt analog zu dem anderen Fall. Mit dem Brent-Verfahren kann folglich der Algorithmus in deterministisch implementiert werden.

Implementierung von Quicksort in MCSTL
Eine parallele Implementierung für Quicksort ist in der MCSTL Bibliothek[8] zu finden. Die zwei Funktionen und stehen zur Verfügung. Der Hauptunterschied bei liegt bei der durch Work stealing realisierten balancierten Lastverteilung. Bei beiden Funktionen ist die Pivotwahl von einem Prozessor und die Partitionierung parallel von mehreren Prozessoren durchgeführt. Die gewünschte Anzahl von Threads, die benutzt werden müssen, wird als Parameter an dem Algorithmus gegeben.


Arbeitsweise
Zuerst wird das Pivotelement gewählt. Dieses ist der Median mehrerer Elementen aus dem Array. Die Partitionierungsphase fängt mit der Aufteilung der Elemente in kleinere Gruppen, auch Chunks genannt, an. Anschließend erhält jeder Thread zwei Chunks zur Verarbeitung. Existieren nicht genügend Chunks um diese Bedingung zu erfüllen, werden weniger Threads als angefordert benutzt. Jeder Thread sortiert seine Elemente, sodass in seinem linken Chunk nur Elemente kleiner als das Pivotelement liegen bzw. nur größere im rechten. Dann reserviert jeder Thread parallel Platz für seine zwei Chunks. Die linken Chunks jedes Threads werden an den Anfang dieses Arrays geschrieben, die rechten Chunks am Ende. Damit ist die Partitionierung beendet.
Balancierte Lastverteilung
In dem ersten Schritt arbeiten alle Prozessoren gemeinsam an der Partitionierung des Arrays. Den zwei erhaltenen partitionierten Teilmengen wird jeweils die Hälfte aller Prozessoren zugewiesen. Im Laufe des Algorithmus wird es zu dem Punkt kommen, in dem jeder Prozessor eine Teilmenge mit mehreren Elementen zu bearbeiten hat. Es kann sein, dass diese Teilmengen verschiedene Längen haben und unterschiedlich lang bearbeitet werden. Infolgedessen haben manche Prozessoren ihre Teilmengen schon partitioniert, während andere noch nicht damit fertig sind. Dabei entsteht Inaktivität von Prozessoren. Die Lösung in besteht aus Prozessor-lokalen Warteschlangen. Wenn ein Prozessor zwei Untermengen nach einer Partitionierung bekommt, dann macht er mit der Partitionierung der größeren weiter, während die kleinere in seine Warteschlange eingefügt wird. Falls die Warteschlange eines Prozessors leer wird, kann dieser Arbeit von der Warteschlange der anderen Prozessoren entnehmen.

Einzelnachweise
- D.J. Evans, R.C Dunbar: The parallel quicksort algorithm part i–run time analysis. In: International Journal of Computer Mathematics. Band 12, Nr. 1, Januar 1982, ISSN 0020-7160, S. 19–55, doi:10.1080/00207168208803323.
- Weixiong Zhang, Nageswara S. V. Rao: Optimal parallel quicksort on EREW PRAM. In: BIT. Band 31, Nr. 1, März 1991, ISSN 0006-3835, S. 69–74, doi:10.1007/bf01952784.
- Quinn, Michael J. (Michael Jay): Instructor's manual to accompany Designing efficient algorithms for parallel computers. McGraw-Hill Book Co, 1987, ISBN 0-07-051072-5.
- Luc Devroye: A note on the height of binary search trees. In: Journal of the ACM. Band 33, Nr. 3, 1. Mai 1986, ISSN 0004-5411, S. 489–498, doi:10.1145/5925.5930.
- Vishkin, U.: Synchronous parallel computation - a survey. Courant Institute of Mathematical Sciences, New York University, April 1983, OCLC 1085604497.
- Richard Cole, Uzi Vishkin: Approximate and exact parallel scheduling with applications to list, tree and graph problems. In: 27th Annual Symposium on Foundations of Computer Science (sfcs 1986). IEEE, 1986, ISBN 0-8186-0740-8, doi:10.1109/sfcs.1986.10.
- Akl, S. G. "Parallel Selection in O(log log n) Time Using O(n/log log n) Processors." Technical Report 88-221, Department of Computing and Information Science, Queen's University, Kingston, Ontario (1988).
- Putze, Felix.: MCSTL: the multi-core standard template library. ACM, 2007, OCLC 854741854.