Open Library
Open Library (englisch für Freie Bibliothek) ist ein Projekt zur kollaborativen Erstellung einer auf einer bibliographischen Datenbank basierenden Online-Bibliothek. Selbsterklärtes Ziel der Open Library ist es, eine eigene Webseite für jedes bislang veröffentlichte Buch zu schaffen. In vielen Fällen wird dabei über den bibliographischen Nachweis hinaus auch der Zugang zum Digitalisat des jeweiligen Buchtitels mit hinterlegtem Volltext ermöglicht.
Als Teilprojekt des Internet Archive wurde die Open Library maßgeblich von Brewster Kahle initiiert und ist am 16. Juli 2007 offiziell ins Leben gerufen worden. Partner des Open-Library-Projekts ist die Open Content Alliance.
Heute sind laut eigenen Angaben 24 Millionen bibliographische Datensätze und die Nachweise und Verknüpfungen zu 1,2 Millionen digitalisierten Büchern in der Open Library enthalten (Stand: November 2009). Die bibliografischen Daten der Open Library sind gemeinfrei (public domain), während der Quellcode unter der GNU Affero General Public License (AGPL) steht.
Die in der Open Library enthaltenen Metadaten stammen von Verlagen, Bibliotheken und Privatpersonen. Dank eines strukturierten Wikis ist es jedem möglich, an der Open Library mitzuarbeiten und Bücher zu katalogisieren oder bereits bestehende Datensätze zu Werken oder Autoren zu editieren.
Die Open Library arbeitet nicht gewinnorientiert.
Inhalte
In der Open Library sind nach eigenen Angaben ca. 30 Millionen Datensätze vorhanden, davon 20 Millionen öffentlich zugänglich und editierbar mit bibliographischen Informationen zu Büchern.[1] Zirka 5 % davon sind auch mit einem Digitalisat des entsprechenden Titels verknüpft.
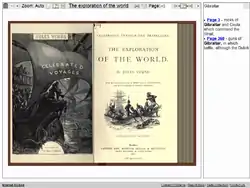
Die in der Open Library nachgewiesenen vollständigen Digitalisate stammen überwiegend aus den im Textarchiv des Internet Archives vorgehaltenen und nicht mehr urheberrechtlich geschützten Buchtiteln sowie von den im Rahmen der Open Content Alliance digitalisierten Büchern. Der Zugriff auf diese Buchdigitalisate erfolgt in der Regel auch über das Textarchiv des Internet Archives. Dort finden sich mittlerweile viele Titel der Google Book Search. Der Internet-Archive-BookViewer ermöglicht das Blättern in digitalisierten Büchern direkt im Browser, sie sind zudem durchsuchbar, da ein OCR-generierter Volltext hinterlegt wurde. In vielen Fällen stehen die Digitalisate dann auch in unterschiedlichen Dateiformaten (unter anderen PDF, EPUB, DjVu) zum Herunterladen zur Verfügung.
Mit der Boston Public Library besteht eine „Scan-on-Demand“-Kooperation: Stößt man in der Open Library auf die Seite eines gemeinfreien Buches, das im Bestand der Boston Public Library und noch nicht gescannt ist, so wird ein Knopf „Scan this book“ angezeigt. Ein Klick auf diesen Knopf bewirkt, dass ein Bibliotheksmitarbeiter vor Ort das Buch aus dem Regal nimmt und es zum „Scanning Center“ bringt, wo es für die Open Library digitalisiert wird.
Technische Grundlagen
Als Webserver verwendet die Open Library einen Lighttpd-Server mit einem FastCGI-Interface. Die Suche basiert auf einem Solr-Suchserver mit einer Lucene-Programmbibliothek.[2]
Als Datenbank wird Infobase genutzt, eine Eigenentwicklung, die speziell für die Zwecke der Open Library entstanden ist: Mit ihr lassen sich beliebig strukturierte große Datenmengen, die von einer großen Zahl an Nutzern erstellt werden, speichern und versionieren. Die Oberfläche basiert auf Infogami, einem strukturierten Wiki basierend auf Python.[3]
Seit dem 6. Mai 2010 präsentiert sich die Open Library mit neuem Layout und erweiterten Funktionen. Mit dem Relaunch ist die Betaphase offiziell beendet, allerdings ist die neue Version noch nicht voll funktionsfähig.[4]
Katalogisierung
Zur Katalogisierung bibliographischer Daten wird ein Formular angezeigt, in das die entsprechenden Daten eingetragen werden können. Hierbei sind keine Pflichtfelder definiert. Für das Feld „Autor“ existiert ein Register, das von jedermann erweitert werden kann. Alle anderen Felder haben kein Register hinterlegt.
Neben der Eingabe der gängigen bibliographischen Daten können auch die DDC und die LoC-Klassifikationen eingetragen werden. Darüber hinaus ist es möglich, ein strukturiertes Inhaltsverzeichnis, eine Beschreibung und den ersten Satz des Buches in das Katalogisat einzupflegen. Zu den Metadaten eines Titels können von den Nutzern auch Buchcover oder Bilder der Autoren hochgeladen werden.
Retrievalfunktionen
Die Open Library bietet sowohl eine einfache als auch eine erweiterte Suche an. Darüber hinaus ist auch ein facettiertes Browsen (Drill-Down) möglich, bei dem die Suchergebnisse durch Ein- und Ausschalten verschiedener Filter modifiziert werden können. Ein Ranking der Trefferlisten, z. B. nach Relevanzkriterien, ist allerdings nicht möglich.
Verknüpfungen mit anderen Diensten
Die einzelnen Titel in der Open Library enthalten Links zu Google Book Search und zu Buchhändlern wie Amazon und AbeBooks. Außerdem wird auf den entsprechenden WorldCat-Eintrag des jeweiligen Buches verwiesen.
Darüber hinaus gibt es die Möglichkeit, mittels maschinenlesbarer Tags von Flickr-Fotos auf Open-Library-Buch- und Autorenseiten zu verlinken.[5]
Verschiedene Open-Library-APIs ermöglichen Mash-ups:[6]
- Über die REST-API sind verschiedene Suchanfragen möglich. Die Antwort erfolgt in JSON oder RDF.[7]
- Über die Books-API lassen sich Informationen zu konkreten Büchern abfragen, durch Angabe der ISBN, OCLC-Nummer, LCCN und der Open-Library-ID OLID. Die Antwort erfolgt im JSON-Format.[8]
- Die Covers-API ermöglicht eine Abfrage von Buchcover- und Autoren-Fotos in drei Größen (klein, mittel, groß). Die Antwort erfolgt im JPG-Format.
Open Library und Bibliotheken
Die Library of Congress, die California State Library und die Boston Public Library kooperieren mit der Open Library (s. a. Inhalte der Open Library). Darüber hinaus sind bereits die Katalogdaten zahlreicher Bibliotheken in Open Library importiert.[9] Im Gegenzug können natürlich auch Bibliotheken über die APIs oder per Bulk-Download die in der Open Library erfassten Metadaten herunterladen und in ihren eigenen Katalog integrieren. So finden sich beispielsweise im Kölner Universitätsgesamtkatalog mittlerweile die Nachweise zu 565.000 der in der Open Library verzeichneten Digitalisate.[10]
OCLC[11] und die British Library[12] befürworten die Open Library hingegen nicht.
Abgrenzung zu LibraryThing
Im Gegensatz zu LibraryThing handelt es sich bei der Open Library nicht um eine Webanwendung zur Verwaltung persönlicher Bibliothekskataloge und Medienlisten. Auch werden in Open Library nicht die einzelnen Exemplare katalogisiert, sondern nur die Metadaten der Bücher. Das erklärt auch den zahlenmäßigen Unterschied: In LibraryThing sind mehr als 45 Millionen Bücher inkl. Exemplardatensätze katalogisiert (Stand: November 2009), in der Open Library die Hälfte (nur Bücher, keine Exemplare). Im Gegensatz zu LibraryThing, wo für bestimmte Anwendungen Gebühren verlangt werden, ist Open Library komplett kostenlos. Der LibraryThing-Gründer Tim Spalding unterstützt die Open Library seit der Entwicklungsphase.[13]
Siehe auch
Weblinks
- Open Library
- Dörte Böhner: Der idealistische Bibliothekar des Internets. Bibliothekarisch.de, 10. März 2009.
- Torsten Kleinz: Die neue Welt-Bibliothek. Zeit online, 15. August 2007.
- Giles Turnbull: A library bigger than any building. BBC News, 31. Juli 2007.
Einzelnachweise
- openlibrary.org
- openlibrary.org
- openlibrary.org
- George Oates: Relaunch is complete! 5. Mai 2010.
- Erläuterung im Open-Library-Blog, siehe auch den Flickr-Blog-Beitrag zu maschinenlesbaren Tags (Memento vom 30. Juni 2012 im Internet Archive)
- Übersicht über die Open-Library-APIs
- Dokumentation der Open-Library-REST-API
- openlibrary.org Dokumentation der Open-Library-Books-API
- openlibrary.org Hier findet sich u. a. eine Liste der Bibliotheken, die bereits Daten an die Open Library geliefert haben.
- Oliver Flimm: 565.000 Digitalisate aus der Open Library im KUG nachgewiesen. (Memento vom 28. Dezember 2009 im Internet Archive) OpenBibBlog, 9. Juni 2009.
- aaronsw.com (Memento vom 3. April 2010 im Internet Archive) Der technische Leiter der Open Library, Aaron Swartz, behauptet in diesem Blogpost, dass OCLC in der Vergangenheit auf verschiedene Arten und Weisen versucht hat, dem Konkurrenten zu schaden, indem Druck auf die Open Library, ihre Finanzierer oder potenzielle Mitgestalter ausgeübt und auf Kooperationsanfragen nicht eingegangen wurde.
- Giles Turnbull: A library bigger than any building. 2007
- librarything.com (Memento vom 1. Juli 2009 im Internet Archive)