Objektrelationale Abbildung
Objektrelationale Abbildung (englisch object-relational mapping, ORM) ist eine Technik der Softwareentwicklung, mit der ein in einer objektorientierten Programmiersprache geschriebenes Anwendungsprogramm seine Objekte in einer relationalen Datenbank ablegen kann. Dem Programm erscheint die Datenbank dann als objektorientierte Datenbank, was die Programmierung erleichtert. Implementiert wird diese Technik normalerweise mit Klassenbibliotheken, wie beispielsweise Entity Framework für .NET-Programmiersprachen, Hibernate für die Programmiersprache Java, Doctrine für PHP, SQLAlchemy für Python, Active Record für Ruby oder Diesel für Rust. Für Java gibt es auch eine standardisierte Schnittstelle, die Jakarta Persistence API.
Prinzip
Objektorientierte Programmiersprachen (OOP) kapseln Daten und Verhalten in Objekten, hingegen legen relationale Datenbanken Daten in Tabellen ab. Die beiden Paradigmen sind grundlegend verschieden. So kapseln Objekte ihren Zustand und ihr Verhalten hinter einer Schnittstelle und haben eine eindeutige Identität. Relationale Datenbanken basieren dagegen auf dem mathematischen Konzept der relationalen Algebra. Dieser konzeptionelle Widerspruch wurde in den 1990er Jahren als object-relational impedance mismatch bekannt.[1]
Um den Widerspruch aufzulösen oder zumindest zu mildern, wurden verschiedene Lösungen vorgeschlagen, beispielsweise objektorientierte Datenbanken oder die Erweiterung von Programmiersprachen um relationale Konzepte (z. B. Embedded SQL). Die direkte objektrelationale Abbildung von Objekten auf Relationen hat den Vorteil, dass einerseits die Programmiersprache selbst nicht erweitert werden muss und andererseits relationale Datenbanken als etablierte Technik in allen Umgebungen als ausgereifte Software verfügbar sind. Nachteil dieses dem OOP-Paradigma entgegenkommenden Ansatzes ist, dass die Stärken und Fähigkeiten von relationalen Datenbanken teilweise nicht genutzt werden, was sich in nicht optimaler Leistung niederschlagen kann.
Grundlegende Techniken
Im einfachsten Fall werden Klassen auf Tabellen abgebildet, jedes Objekt entspricht einer Tabellenzeile und für jedes Attribut wird eine Tabellenspalte reserviert. Die Identität eines Objekts entspricht dem Primärschlüssel der Tabelle. Hat ein Objekt eine Referenz auf ein anderes Objekt, so kann diese mit einer Fremdschlüssel-Primärschlüssel-Beziehung in der Datenbank dargestellt werden.
Der Begriff Shadow Information („Schatteninformation“) bezeichnet zusätzliche Daten, die ein Objekt benötigt, um persistent abgelegt zu werden.[2] Dazu gehören Primärschlüssel – speziell wenn es sich um Surrogatschlüssel ohne fachliche Bedeutung handelt – sowie Hilfsdaten für die Zugriffssteuerung, beispielsweise Zeitstempel.
Abbildung von Vererbungshierarchien
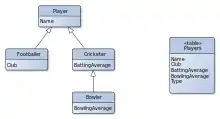
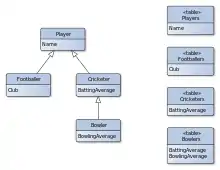
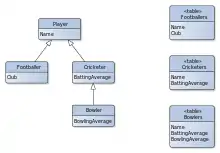
Es gibt im Wesentlichen drei verschiedene Verfahren, um Vererbungshierarchien auf Datenbanktabellen abzubilden. Einige Frameworks bieten weitere Variationen und Vermischungen dieser drei Grundverfahren.[3]
- Tabelle pro Vererbungshierarchie[4]
- (auch Single Table, einzelne Tabelle) Bei diesem Verfahren werden alle Attribute der Basisklasse und aller davon abgeleiteten Klassen in einer gemeinsamen Tabelle gespeichert. Zusätzlich wird ein sogenannter „Diskriminator“ in einer weiteren Spalte abgelegt, der festlegt, welcher Klasse das in dieser Zeile gespeicherte Objekt angehört. Attribute von abgeleiteten Klassen dürfen bei diesem Ansatz aber in den meisten Fällen nicht mit einem NOT-NULL-Constraint versehen werden. Außerdem können Beschränkungen der Anzahl erlaubter Spalten pro Tabelle diesen Ansatz bei großen Klassen bzw. Klassenhierarchien vereiteln.
- Tabelle pro Unterklasse[4]
- (auch Joined oder Class Table) Bei diesem Verfahren wird eine Tabelle für die Basisklasse angelegt und für jede davon abgeleitete Unterklasse eine weitere Tabelle. Ein Diskriminator wird nicht benötigt, weil die Klasse eines Objekts durch eine 1-zu-1-Beziehung zwischen dem Eintrag in der Tabelle der Basisklasse und einem Eintrag in einer der Tabellen der abgeleiteten Klassen festgelegt ist.
- Tabelle pro konkrete Klasse[4]
- (auch Table per Class oder Concrete Table) Hier werden die Attribute der abstrakten Basisklasse in die Tabellen für die konkreten Unterklassen mit aufgenommen. Die Tabelle für die Basisklasse entfällt. Der Nachteil dieses Ansatzes besteht darin, dass es nicht möglich ist, mit einer Abfrage Instanzen verschiedener Klassen zu ermitteln.
Ein weiteres Verfahren ist die Abbildung von Strukturen (Beziehungen, Vererbung) und Daten in generellen Tabellen General Tables. Dabei enthält die gesamte Datenbank genau 5 Tabellen: Eine für Klassen, eine für Beziehungen (einschließlich Vererbungsbeziehungen), eine für Attribute, eine für Instanzen (der Klassen) und eine für Werte (der Attribute).[5] Dieses Verfahren hat allerdings in der Praxis kaum Bedeutung.
Literatur
- Scott W. Ambler: Agile Database Techniques. Wiley & Sons, 2003, ISBN 0-471-20283-5 (agiledata.org [abgerufen am 22. Oktober 2007]).
Einzelnachweise
- Ted Neward: The Vietnam of Computer Science. (Nicht mehr online verfügbar.) Interoperability Happens, 26. Juni 2006, archiviert vom Original am 22. Januar 2018; abgerufen am 2. Juni 2010 (englisch).
- Scott W. Ambler: Agile Database Techniques. 2003, S. 228–229.
- Chapter 10. Inheritance Mapping. In: Hibernate Reference Documentation. Red Hat Middleware, LLC, 2012, abgerufen am 31. Juli 2012 (englisch).
- Martin Fowler: Patterns of Enterprise Application Architecture. Addison-Wesley-Longman, Amsterdam 2002, ISBN 0-321-12742-0.
- Map Classes To A Generic Table Structure