Föderales Lernen
Föderales Lernen beschreibt eine Technik im Bereich des maschinellen Lernens, bei der ein Modell auf mehreren Geräten trainiert wird. Jedes teilnehmende Gerät verfügt über einen eigenen lokalen Datensatz, der nicht mit anderen Teilnehmern ausgetauscht wird. Im Gegensatz dazu gibt es beim herkömmlichen maschinellen Lernen einen zentralen Datensatz.
Durch diese Technik bauen mehrere Teilnehmer ein gemeinsames robustes Modell unter Berücksichtigung kritischer Probleme wie Datenschutz, Datensicherheit, Zugriffsrechte und Zugang zu heterogenen Daten auf. Die Technik wird in vielen Bereichen wie in der Verteidigung, der Telekommunikation, dem Internet der Dinge und dem Gesundheitswesen angewandt.
Definition und Merkmale
Föderales Lernen zielt darauf ab, ein Machine-Learning-Modell wie tiefe neuronale Netze auf mehreren teilnehmenden Knoten mit jeweils lokalen Datensätzen zu trainieren, ohne die Daten explizit auszutauschen. Das kann dadurch geschehen, dass das Modell auf allen Knoten einzeln trainiert wird und sich die Teilnehmer die Aktualisierungen der Modellparameter in regelmäßigen Abständen gegenseitig mitteilen. Dadurch kann ein gemeinsames Modell hergestellt werden.
Der wesentliche Unterschied zwischen föderalem und verteiltem Lernen besteht in den Annahmen über die Eigenschaften der lokalen Datensätze.[1] Während verteiltes Lernen primär auf die Parallelisierung der Berechnungen abzielt, ist der Hauptaspekt von föderalem Lernen die Heterogenität der Daten. Beim verteilten Lernen findet sich gewöhnlich die Annahme, dass die lokalen Datensätze identisch verteilt sind und die Knoten über in etwa die gleiche Datenmenge verfügen. Im Gegensatz dazu muss beim föderalen Lernen eine identische Verteilung und eine gleiche Datenumfang nicht gegeben sein. Darüber hinaus können Teilnehmer bezüglich ihrer Verfügbarkeit unzuverlässig sein (bspw. Smartphones oder IoT-Geräte).[2]
Zentralisierter Ansatz
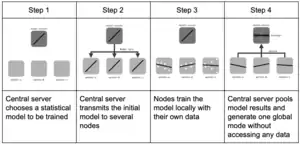
Beim zentralisierten föderalen Lernen wird ein zentraler Server genutzt, um die verschiedenen Schritte des Lernprozesses auf den teilnehmenden Knoten zu koordinieren. Der Server ist für die Knotenauswahl am Anfang des Trainings und das Zusammenfügen der Modellparameteraktualisierungen zuständig. Da alle Knoten über den Server kommunizieren, kann er zum Flaschenhals werden.
Dezentralisierter Ansatz
Beim dezentralisierten föderalen Lernen koordinieren die teilnehmenden Knoten sich selbst, um ein gemeinsames Modell zu erhalten. Dadurch wird beim Ausfall eines einzelnen Teilnehmers der Ausfall des gesamten Systems verhindert.[2]
Iteratives Lernen
Das Training eines gemeinsamen Modells erfolgt in einem iterativen Prozess. Je nach Ansatz wird das globale Modell zunächst zu den Nodes übertragen. Anschließend erfolgt dort das lokale Training. Die Aktualisierungen der Modellparameter werden dem zentralen Koordinator oder den anderen Teilnehmern direkt übertragen und dort aggregiert und verarbeitet, um ein aktualisiertes globales Modell zu erstellen.[2]
Eigenschaften
Privacy by Design
Ein großer Vorteil von föderalem Lernen besteht darin, dass lokale Datensätze nicht zusammengeführt und zu einem zentralen Rechner übertragen werden müssen, wodurch der Datenschutz einfacher gewährleistet werden kann. Stattdessen werden während des Trainings nur Modellparameter oder Parameteraktualisierungen übertragen.
Die Aktualisierungen können zusätzlich verschlüsselt werden, um den Datenschutz weiter zu verbessern, zum Beispiel durch eine homomorphe Verschlüsselung, die es erlaubt, bestimmte Berechnungen durchzuführen, ohne die Daten vorher zu entschlüsseln. Trotz solcher Vorkehrungen können Parameter weiterhin Informationen über die zugrundeliegenden Daten preisgeben.
Personalisierung
Das erstellte Modell kann für Vorhersagen erstellen, die auf Mustern basieren, die von allen Knoten gemeinsam gelernt wurden. Darüber hinaus ist es möglich, weitere lokale Modelle zu erstellen, die auf die Besonderheiten eines Teilnehmers angepasst sind – sogenanntes Multi-Task Learning. Die Teilnehmer können dazu auch in Cluster eingeteilt werden, die Gemeinsamkeiten aufweisen.[3]
Im Falle von tiefen neuronalen Netzen ist es zum Beispiel möglich, die ersten Schichten zwischen allen Knoten zu teilen und die letzten nur lokal zu trainieren.[4]
Kommunikationsaufwand
Es ist bekannt, dass hohe Kommunikations-Overheads aufgrund häufiger Gradientenübertragungen FL verlangsamen. Um die Kommunikations-Overheads abzuschwächen, wurden zwei Haupttechniken untersucht: (i) lokale Aktualisierung von Gewichtungen, die den Kompromiss zwischen Kommunikation und Berechnung charakterisieren, und (ii) Gradientenkompression, die den Kompromiss zwischen Kommunikation und Präzision charakterisieren[5].
Einzelnachweise
- Jakub Konečný, Brendan McMahan, Daniel Ramage: Federated Optimization: Distributed Optimization Beyond the Datacenter. 2015, arxiv:1511.03575.
- Peter Kairouz, H. Brendan McMahan, Brendan Avent et al.: Advances and Open Problems in Federated Learning. 2019, arxiv:1912.04977.
- Felix Sattler, Klaus-Robert Müller, Wojciech Samek: Clustered Federated Learning: Model-Agnostic Distributed Multi-Task Optimization under Privacy Constraints. 2019, arxiv:1910.01991.
- Manoj Ghuhan Arivazhagan, Vinay Aggarwal, Aaditya Kumar Singh, Sunav Choudhary: Federated Learning with Personalization Layers. 2019, arxiv:1912.00818.
- Khademi Nori Milad, Yun Sangseok, Kim Il-Min: Fast Federated Learning by Balancing Communication Trade-Offs. 23. Mai 2021, arxiv:2105.11028.