Data-Lineage
Data-Lineage bzw. Datenherkunft (auch Data Provenance oder Data Pedigree, deutsch auch Datenabstammung und -stammbaum) bezeichnet in einem Data-Warehouse-System (Datenlager) die Fragestellung, zu gegebenen aggregierten Datensätzen die ursprünglichen Datensätze zu bestimmen, aus denen sie entstanden sind.
Üblicherweise werden in einem Data-Warehouse-System Daten aus verschiedenen Quellen extrahiert, nach bestimmten Regeln transformiert und zur Analyse bereitgestellt (siehe ETL-Prozess). Beim Data-Lineage muss der umgekehrte Weg beschrieben werden, um von Analyseergebnissen zu den Quellen zu gelangen. Dazu werden die Transformationen mathematisch modelliert, um für gegebene Ausgabewerte einer Transformation die dazugehörenden Eingabewerte zu bestimmen (siehe auch EVA-Prinzip).
Transformationen
Alle Verarbeitungsschritte werden als Transformation modelliert, die aus einer Eingabe eine Ausgabe erzeugen: . Die Lineage eines Datensatzes der Ausgabe ist definiert als die Teilmenge der Eingabe, die an der Konstruktion von beteiligt war: . Die Lineage einer Menge von Datensätzen setzt sich aus der Lineage ihrer Elemente zusammen.








Alle Transformationen lassen sich in drei Klassen einteilen. Dabei wird davon ausgegangen, dass die Transformationen stabil und deterministisch sind, das heißt, es werden keine neuen Ausgabeobjekte erfunden und die Ausgabe ist bei gleicher Eingabe konstant.
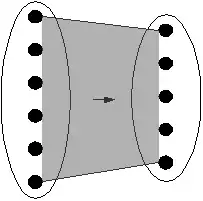
Blackbox
Eine Blackbox ist eine Transformation, über die sich keine speziellen Eigenschaften angeben lassen. Jedes Element der Ausgabe kann von jedem Element der Eingabe abhängen. Ein Beispiel für eine Blackbox ist eine Funktion, die für jede Zahl einer Menge die Abweichung vom Mittelwert angibt. Die Data-Lineage ist somit die gesamte Eingabe:

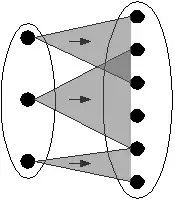
Dispatcher
Ein Dispatcher ist eine Transformation, die Elemente der Eingabe unabhängig voneinander behandelt. Jedes Eingabeelement kann beliebig viele Ausgabeelemente erzeugen (auch Null). Die Lineage eines Elements der Ausgabe eines Dispatchers setzt sich aus allen Elementen der Eingabe zusammen, für die gilt, dass an der Transformation zu beteiligt war:


Ein Spezialfall eines Dispatchers ist ein Filter. In einem Filter erzeugt jedes Eingabeelement entweder sich selbst oder gar keine Ausgabe. Die Lineage eines Filters entspricht genau der Ausgabe:
- .

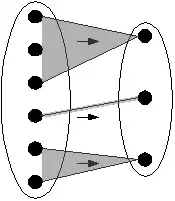
Aggregator
Ein Aggregator ist eine Transformation, bei der jedes Eingabeelement an mindestens einem Ausgabeelement beteiligt ist und sich die Eingabe so in disjunkte Partitionen teilen lässt, dass jede Partition genau für ein Ausgabeelement verantwortlich ist. Jedes Element der Ausgabe lässt sich so eindeutig einer Gruppe von Eingabeelementen zuordnen. Die Lineage eines bestimmten Ausgabeelements entspricht seiner Eingabepartition:


Ein spezielles Beispiel von Aggregatoren sind schlüsselerhaltende Aggregatoren, bei denen nur Eingabeelemente mit einem übereinstimmenden Schlüsselattribut das gleiche Ausgabeelement erzeugen, in dem der gleiche Schlüssel vorkommt.
Eine weitere Klasse von Aggregatoren sind kontextfreie Aggregatoren, bei denen die Zuordnung eines Eingabeelements zu einer bestimmten Partition unabhängig von den Werten anderer Eingabeelemente erfolgt.
Eine Transformation, die alle Eingabeobjekte auf sich selber abbildet (Identität) oder jedes Eingabeelement einer einfachen Berechnung unterwirft (z. B. Formatumwandlung) ist gleichzeitig Dispatcher und Aggregator und wird auch als Filter bezeichnet.
Berechnung der Data-Lineage
Die Data-Lineage einer gegebenen Ausgabe lässt sich bei bekannter Eigenschaft der Transformation mit einer Tracing-Prozedur bestimmen.
- Für Dispatcher wird jedes Element der Eingabe geprüft, ob es die Ausgabe erzeugt und in diesem Fall zur Data-Lineage hinzugefügt.
- Für kontextfreie Aggregatoren werden zunächst die Partitionen gebildet und dann diejenige gewählt, die zur Ausgabe führt. Die Partionen werden ermittelt, indem die Eingabeelemente sukzessive zu bereits vorhandenen Partitionen hinzugefügt werden, falls dabei die Größe der Ausgabe gleich einem Element bleibt.
- Für schlüsselerhaltende Aggregatoren werden die Schlüssel der Eingabeelemente überprüft.
- Für Filter entspricht die Data-Lineage der Ausgabe
Für allgemeine Aggregatoren oder Black Boxes ist der Aufwand für ein Tracing zu groß, da Potenzmengen der Eingabeelemente gebildet werden müssten. Deshalb muss zur effektiven Ermittlung der Data-Lineage einer Transformation entweder eine explizite Tracingprozedur bekannt sein oder eine Inverse Funktion benutzt werden. Die Inverse Funktion einer Transformation ist nur bei Aggregatoren als Tracingprozedur nutzbar, da sie nicht unbedingt eindeutig ist.
Um für eine ganze Kette von Transformationen die Data-Lineage zu bestimmen ohne alle Zwischenergebnisse speichern zu müssen, werden die Transformationen normalisiert, indem man einige von ihnen zusammenfasst, ohne dass die speziellen Eigenschaften (Aggregator, Dispatcher, Filter…) verloren gehen, so dass ein effektives Tracing möglich ist. Die Bestimmung der optimalen Sequenz für das Tracing einer hintereinander geschalteten Reihe von Transformationen hängt auch von dem jeweiligen Kostenmodell ab.
Literatur
- Yingwei Cui, Jennifer Widom. Lineage Tracing for General Data Warehouse Transformations. In: Proceedings of the 27th International Conference on Very Large Data Bases (VLDB'01). 2001.