Construction-Integration-Modell
Das Construction-Integration-Modell (englisch Konstruktions-Integrations-Modell) ist ein psychologisches Prozessmodell des Textverstehens, das auf Walter Kintsch und Teun van Dijk zurückgeht. Das Modell ist damit in den Schnittbereich der Psycholinguistik und der Kognitionswissenschaft einzuordnen.
Alle folgenden Aussagen beziehen sich sowohl auf das Lesen und Verstehen eines geschriebenen Textes wie auch auf das Hören und Verstehen eines Diskurses.
Propositionale Bedeutungsrepräsentation
Eine Grundlage des Modells ist der Begriff der Proposition als Bedeutungsrepräsentation. Propositionen bestehen aus einem Prädikat und einem oder mehreren Argumenten, die durch das Prädikat in Beziehung gesetzt werden. Propositionen werden folgendermaßen notiert:
- P1: LIEBEN(HANS,INGE)
Vor dem Doppelpunkt wird angegeben, um welche Proposition es sich handelt, damit in der späteren Analyse einfacher darauf Bezug genommen werden kann. Das Prädikat (hier: LIEBEN) bringt die Argumente HANS und INGE in Beziehung zueinander. P1 drückt also folgenden natürlichsprachlichen Satz aus: S1: „Hans liebt Inge.“ Zu beachten ist, dass Prädikate und Argumente Konzepte sind, also Bedeutungen, Referenten oder Denotate von Wörtern. Aus diesem Grund werden sie meist in Großbuchstaben oder auch Kapitälchen notiert.
Außer Konzepten können auch andere Propositionen Argumente sein. Der natürlichsprachliche Satz: „Weil Peter eine Reifenpanne hat, muss er warten.“ wird somit folgendermaßen propositional gefasst:
- P2: WEIL(P3,P4)
- P3: HABEN(PETER,REIFENPANNE)
- P4: MÜSSEN(PETER,P5)
- P5: WARTEN(PETER)
oder
- P6: WEIL(HABEN(PETER,REIFENPANNE),MÜSSEN(PETER,WARTEN(PETER)))
P2 verknüpft hier die Proposition P3 und P4 kausal und P5 ist in P4 eingebettet. Es herrscht hier also eine Argumentüberlappung. P6 ist lediglich eine kompaktere und unübersichtlichere Darstellungsweise für P2 bis P5.
Das Construction-Integration-Modell des Textverstehens
Es wird davon ausgegangen, dass der/die Leser beim Lesen eines Textes diesen in eine propositionale Repräsentation überführt. Hierbei unterscheidet man die Phase der Konstruktion von der Phase der Integration.
Konstruktionsphase
In der Konstruktionsphase wird der Bedeutungsgehalt des Textes in propositionaler Form extrahiert. Es entsteht ein propositionales Netzwerk, in dem die Propositionen miteinander über Argumentüberlappung (s. o.) verbunden sind. Dieses Netzwerk muss zunächst nicht vollständig verbunden sein. Das heißt, es kann mehrere kleine, voneinander unabhängige Netzwerke geben. Der Leser wird nun versuchen, ein kohärentes, also ein einheitliches, voll verbundenes Netzwerk herzustellen. Hierzu bedarf es in den meisten Fällen einer Vielzahl an Assoziationen und Inferenzen (Schlussfolgerungen) aus dem Wissen des Lesers. Folgendes Beispiel soll das verdeutlichen:
Der Mini-Text
- „Peter hatte eine Reifenpanne. Nachdem er das Rad gewechselt hatte, konnte er weiterfahren.“
enthält explizit folgende Propositionen:
- P7: HABEN(PETER,REIFENPANNE)
- P8: NACHDEM(P9,P10)
- P9: WECHSELN(PETER,RAD)
- P10: KÖNNEN(PETER,P11)
- P11: WEITERFAHREN(PETER)
Diese Propositionen würden jedoch nicht genügen, um eine kohärente Repräsentation dieses Textes zu erstellen. Hierzu müssten Inferenzen und Assoziationen hervorgebracht werden wie beispielsweise: „Nicht Peter hat eine Reifenpanne, sondern das Gefährt, in dem Peter sitzt.“ und: „Ein Gefährt kann nicht mehr fahren, wenn es eine Reifenpanne hat.“
Die Assoziationen und Inferenzen, die während der Konstruktionsphase hervorgebracht werden, sind ungeleitet, zum Teil chaotisch und idiosynkratisch, also nur für den verstehenden Menschen selbst verständlich. Der Konstruktionsprozess ist somit ein klassischer Bottom-up-Prozess.
Nachdem diese Inferenzen alle gezogen wurden und die entsprechenden Propositionen ebenfalls in das propositionale Netzwerk integriert sind, übernimmt der Integrationsprozess.
Integrationsprozess
Der Integrationsprozess übernimmt aus der Konstruktionsphase salopp ausgedrückt ein chaotisches Propositionennetzwerk, in dem Wichtiges, Unwichtiges und zum Teil auch Widersprüchliches miteinander verbunden ist. Nun beginnt ein Constraint-Satisfaction-Prozess, der die Aktivationswerte für die verschiedenen Knoten im Netzwerk, also die Propositionen so anpasst, dass allen Constraints (Beschränkungen, Widersprüche usw.) Rechnung getragen wird – das Netz wird integriert. Dabei können unwichtige Propositionen wegfallen, widersprüchliche Informationen bereinigt werden und kontextuelle Einflüsse (eine von mehreren Top-down-Komponenten im Modell) zur Geltung kommen. Der Constraint-Satisfaction-Prozess läuft über mehrere Zyklen, in denen nach dem Prinzip der Aktivationsausbreitung (spreading activation) die Aktivationswerte für die Knoten angepasst werden.
Anmerkung
Konstruktion und Integration laufen nicht nacheinander, sondern simultan ab. Das heißt, während ein Wort verarbeitet wird, wird die bis zu diesem Punkt bereits aufgebaute Bedeutungsrepräsentation integriert. Das neue Wort wird in das Netz eingebaut, und der Integrationsprozess geht weiter während bereits wieder das nächste Wort verarbeitet wird.
Textbasis und Situationsmodell
Es lässt sich bei den Repräsentationsstrukturen theoretisch unterscheiden zwischen Textbasis und Situationsmodell. Es ist zu beachten, dass dies eine theoretische Unterscheidung ist, da diese Konstrukte keine unabhängigen Strukturen darstellen. Zum Zwecke der Analyse lassen sie sich jedoch trennen.
Die Textbasis repräsentiert alle im Text explizit genannten Propositionen. Diese Textbasis kann somit fast niemals vollständig kohärent sein, da ein Text, in dem wirklich alle Informationen explizit genannt sind, nicht vorstellbar ist (vgl. auch den Minitext oben). Es wird immer Assoziationen und Wissenselaborationen benötigen, um eine kohärente Repräsentation eines Textes im Geist des Verstehenden herzustellen.
Jede Anreicherung der Textbasis mit Wissenselementen des Lesers führt zu einem Situationsmodell. Diese theoretische Ebene wurde 1983 in das Construction-Integration-Modell aufgenommen, was – wie Kintsch explizit schreibt – auf den großen Einfluss der Theorie der Mentalen Modelle von Johnson-Laird zurückzuführen ist.
Situationsmodelle bestehen also aus der Textbasis sowie den Anreicherungen aus dem Wissen des Lesers. Dabei ist anzumerken, dass Situationsmodelle nicht mehr rein propositional repräsentiert sein müssen. Auch bildhafte oder prozessartige Situationsmodelle sind denkbar, dies hängt unter anderem vom Ziel des Lesers ab. Will der Leser bspw. eine Textaufgabe lösen, wird er zusätzlich ein sogenanntes Problemmodell hervorbringen, das die arithmetischen Operationen repräsentiert, die zur Lösung der Aufgabe führen können. Eine Textaufgabe kann somit inhaltlich (auf der Ebene der Textbasis) verstanden sein, der Leser kann auch eine Vorstellung davon haben, was in der Aufgabe beschrieben wird (Situationsmodell). Das heißt aber nicht, dass er auch weiß, was rechnerisch zu tun ist, um zur Lösung des Problems zu gelangen (Problemmodell).
Mikro- und Makrostruktur
Eine Unterscheidung, die orthogonal zu jener zwischen Textbasis und Situationsmodell vorgenommen wird, ist jene zwischen Mikro- und Makrostruktur. Dabei besteht die Mikrostruktur aus den Mikropropositionen. Das sind jene Propositionen, die aus dem Text extrahiert werden können und die Assoziationen, die aus dem Wissen des Lesers hinzutreten. Diese sind in keiner Weise hierarchisch organisiert.
Genau das geschieht in der Makrostruktur, die der Mikrostruktur eine hierarchische Gliederung (oder Organisation) verleiht. Dazu werden sogenannte Makropropositionen anhand von drei Makroregeln konstruiert:
- Selektion/Löschung: Jede Proposition, die keine Interpretationsbedingung einer anderen Proposition darstellt, kann gelöscht werden
- Generalisierung: Kann jede Proposition P1, P2, P3, … einer Menge an Propositionen durch eine andere Proposition MP1 ausgedrückt werden, kann P1, P2, P3, … jeweils durch MP1 ersetzt werden.
- Beispiel:
- P12: MÖGEN(PETER,DALMATINER)
- P13: MÖGEN(PETER,BERHARDINER)
- P14: MÖGEN(PETER,LANGHAARDACKEL)
- P15: MÖGEN(PETER,SCHÄFERHUNDE)
- P12, P13, P14 und P15 können jeweils ausgetauscht werden mit
- MP1: MÖGEN(PETER,HUNDE)
- Dies ist eine Generalisierung auf dem Wissenshintergrund, dass Dalmatiner, Bernhardiner, Langhaardackel und Schäferhunde alles Hunde sind und so verschieden, dass Peter wohl tatsächlich alle Hunde mag. Wie hier gut zu sehen ist, müssen Makropropositionen nicht formal-logisch korrekt sein.
- Konstruktion: Kann die Sequenz der Propositionen P1, P2, P3, … durch eine andere Proposition MP1 ausgedrückt werden, kann die Sequenz P1, P2, P3, … durch MP1 ersetzt werden.
- Beispiel:
- P16: AUSDEHNEN(HERZMUSKEL)
- P17: ZUSAMMENZIEHEN(HERZMUSKEL)
- P16 und P17 können beide gemeinsam ersetzt werden von:
- MP2: PUMPEN(HERZ)
- Auch diese Konstruktion einer völlig neuen Proposition (genauer: einer Makroproposition) geschieht vor dem Hintergrund des Wissens des lesenden Menschen.
Welche Makropropositionen und welche Makrostruktur wann herausgebildet werden/wird, ist hoch kontextabhängig. Es hängt von der Art des Textes, den Erwartungen und Zielen des Lesers, den äußeren Umständen und natürlich vom Wissen des Lesers ab, welche hierarchische Organisation die Repräsentation der Textbedeutung im Geist des Lesers annimmt.
Es kann jedoch klare Hinweise auf die Herausbildung einer ganz bestimmten Makrostruktur im Text geben. Dazu gehören Zwischenüberschriften, Gliederungshinweise, als besonders wichtig herausgestellte Aussagen usw.
Auch über diese kann sich ein einzelner Leser jedoch hinwegsetzen. Stellen wir uns folgendes Szenario vor: Wir lesen einen Text über die Wirtschaft, die Regierung, die Umwelt und die Bevölkerungsstruktur Brasiliens und Argentiniens. Der Text ist so aufgebaut, dass zu jedem der einzelnen Bereiche immer erst Brasilien und dann Argentinien besprochen wird. Folgende Makrostruktur legt der Text also nahe:
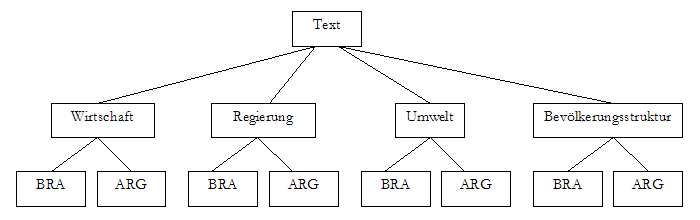
Wenn wir uns nun aber sehr für Brasilien und überhaupt nicht für Argentinien interessieren, werden wir eine andere Makrostruktur herausbilden, obwohl wir denselben Text lesen. Diese könnte eventuell so aussehen:
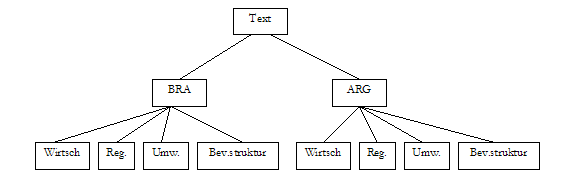
Wenn wir uns für Brasilien mehr interessieren, ist außerdem davon auszugehen, dass in der linken Hälfte des Schaubilds eine viel reichhaltigere Repräsentation (d. h. mehr Assoziationen und Elaborationen) vorliegt als in der rechten.
Empirische Studien
Im Folgenden werden Literaturverweise auf empirische Studien zum Construction-Integration-Modell mit einem kurzen Kommentar genannt. Diese stellen nur eine kleine Auswahl dar.
- W. Kintsch, J. Keenan: Reading Rate and Retention as a Function of the Number of Propositions in the Base Structure of Sentences. In: Cognitive Psychology, 5, 1973, S. 257–274.
Eine klassische empirische Studie zu Lesezeiten und Behaltensleistung in Abhängigkeit zur Anzahl der Propositionen in einem Satz. Diese Studie muss als Vorläufer des Construction-Integration-Modells gesehen werden. - W. Kintsch: Learning from Text. In: Cognition and Instruction, 3(2), 1986, S. 87–108.
Eine Studie mit zwei interessanten Studien zu Situationsmodell und Textbasis, die in Experiment 2 gar einen interessanten Gender-Aspekt aufwirft. - Till et al.: Time course of priming for associate and inference words in a discourse context. In: Memory & Cognition, 16, 1988, S. 283–298.
Überaus interessante Studie zum zeitlichen Ablauf des Construction-Integration-Prozesses, hier wird der sogenannte activation-selection-elaboration-Ansatz vorgestellt. - F. Schmalhofer, M. A. McDaniel, D. Keefe: A Unified Model for Predictive and Bridging Inferences. In: Discourse Processes, 33(2), 2002, S. 105–132.
Eine interessante Studie zu Inferenzen aus dem Wissen des Lesers. - S. Mehl: Fiktion und Identität im Fall Esra. Mehrdisziplinäre Bearbeitung eines Gerichtsverfahrens. LIT Verlag, Berlin u. a. 2014, Kap. 4.
Eine umfassende empirische Anwendung des Modells auf den Fall Esra (Roman).
Siehe auch
Literatur
- I. Barshi: Message length and misunderstandings in aviation communication: Linguistic properties and cognitive constraints. University of Colorado, Boulder 1997.
- W. Kintsch: The representation of meaning in memory. Erlbaum, Hillsdale 1974.
- W. Kintsch: The Role of Knowledge in Discourse Comprehension: A Construction-Integration Model. In: Psychological Review, 95(2), 1988, S. 163–182.
- W. Kintsch: Comprehension: A Paradigm for Cognition. Cambridge University Press, Cambridge 1998.
- W. Kintsch: An Overview of Top-Down and Bottom-Up Effects in Comprehension: The CI Perspective. In: Discourse Processes, 39(2&3), 2005, S. 125–128, doi:10.1080/0163853X.2005.9651676
- W. Kintsch, J. G. Greeno: Understanding and solving word arithmetic problems. In: Psychological Review, 92(1), 1985, S. 109–129.
- W. Kintsch, V. L. Patel, K. A. Ericsson: The role of long-term working memory in text comprehension. In: Psychologia, 42, 1999, S. 186–198.
- W. Kintsch, T. Van Dijk: Toward a model of text comprehension and production. In: Psychological Review, 85, 1978, S. 363–394.
- W. Kintsch, J. J. Yarborough: Role of rhetorical structure in text comprehension. In: Journal of Educational Psychology, 74, 1982, S. 828–834.
- T. Van Dijk, W. Kintsch: Strategies of discourse comprehension. Academic Press, New York 1983.
- Ilka Hanne Unsöld: Die Bildung von Inferenzen bei der kognitiven Verarbeitung medialer Texte. Eine Untersuchung an Kindern und Erwachsenen. Verlag Dr. Kovac, Hamburg 2008, ISBN 978-3-8300-3852-8.