Übersetzungsspeicher
Ein Übersetzungsspeicher (auch Übersetzungsarchiv; engl. translation memory[1], abgekürzt TM) ist eine Datenbank mit strukturierten Übersetzungen, die die Hauptkomponente von Anwendungen zur rechnerunterstützten Übersetzung (Computer-aided translation, abgekürzt CAT) darstellt.
Datenbankstruktur
Beim Aufbau der Datenbank gibt es zwei grundsätzliche Typen:
- Zum einen gibt es Datenbanken, bei denen die gespeicherten Segmente zusammengehörige Texte sind [getrennt nach Ausgangs- (ling. „Quellsprache“) und Zielsprache]. Diese Systeme haben den Vorteil, dass keine isolierten Sätze gespeichert werden, sondern jeder Satz im Kontext. Außerdem kann die Datenbankabfrage auf bestimmte Themen eingeschränkt und damit die Anzeige der Treffer beschleunigt werden.
- Zum anderen gibt es Datenbanken, bei denen die Segmente Sätze oder Absätze sind, die isoliert, also ohne den Kontext der Quelltexte gespeichert werden. Die Antwortzeiten hängen aber nicht so sehr von der Größe der Einheiten ab als von der effizienten Indizierung in der Datenbank.
Praktisches Arbeiten
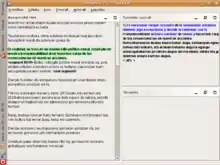
In der Praxis beginnt die Arbeit mit einem Übersetzungsspeicher damit, dass ein Quelltext direkt aus der Textverarbeitung heraus aufgerufen wird oder bei eigenständigen TM-Programmen importiert wird. Das Programm sucht dann im Speicher nach Formulierungen mit einer vorgegebenen Mindestübereinstimmung und bietet sie als Übersetzung an. Diese Übersetzungen können vom Bearbeiter übernommen, abgelehnt oder angepasst werden. Werden keine passenden Segmente gefunden, gibt der Bearbeiter eine neue Übersetzung ein, die er dann mit dem Ausgangssegment speichern lassen kann. Wenn er das tut, wird sie ab dann beim Auftreten ähnlicher Segmente vorgeschlagen. Wenn die Segmente mit Zusatzangaben versehen werden, erleichtert das später die Auswahl zwischen mehreren Vorschlägen. Zu solchen Angaben gehören:
- Benutzer, von dem die gespeicherte Übersetzung stammt (angelegtes/geändertes Segment)
- Datum der Erstellung/Änderung des Segments
- Häufigkeit der Formulierung
- Kontext der Formulierung
- Weitere klassifizierende Angaben
Diese Zusatzangaben werden vom Programm entweder automatisch zugewiesen oder müssen vom Übersetzer manuell gepflegt werden.
Bei der Erkennung, inwieweit der gesuchte Text einem bereits gespeicherten Ausgangstextsegment ähnelt, wertet die Software je nach Voreinstellung neben den Buchstabenfolgen des Textes auch Satzzeichen, Leerzeichen, Absatzmarken und unter Umständen sogar Formatierungen aus.
Programmtechnische Eigenschaften
Üblicherweise verfügen TM-Systeme über Funktionen, die das Erkennen einer verwertbaren Übersetzung unabhängig von variablen Elementen wie Zahlen, Datumsangaben, Maßeinheiten oder Eigennamen ermöglichen.
Die Suche nach ähnlichen Quellsegmenten erfolgt mittels unterschiedlich aufwändiger Suchalgorithmen (unscharfe Suche), die dann auch einen meist prozentualen Ähnlichkeitswert angeben.
Um Texte aus Textverarbeitungs- und DTP-Programmen für die TM-Systeme verfügbar zu machen, gibt es Filter- und Extraktionsprogramme, die den Quelltext aus den jeweiligen Dateien herauslösen. Im Ergebnis erhält man dann eine markierte („getaggte“) Datei, in welcher der zu übersetzende Text zwischen speziellen Steuercodes (Tags) verfügbar ist. Diese Layout-Tags werden vom System geschützt bzw. ausgeblendet, sodass sie nicht versehentlich überschrieben oder verändert werden können. Bei der Übersetzung von Software (Lokalisierung) kann der Programmcode auf diese Weise vor unbeabsichtigter Veränderung geschützt werden. Nach der Übersetzung dienen die Steuercodes dem Filterprogramm dazu, die Texte wieder an die korrekte Stelle in der DTP-Datei einzufügen und dabei auch Formatierungen (zum Beispiel Fettdruck, kursiv, …) auf die entsprechenden Stellen der Übersetzung anzuwenden.
Die meisten TM-Systeme verfügen über spezielle Editoren, um die Arbeit mit diesen „getaggten“ Dateien zu erleichtern.
Beim Austausch zwischen verschiedenen TM-Systemen kann man Translation Memories über das TMX-Format (Translation Memory eXchange) und Projekte über das XML Localization Interchange File Format (XLIFF) austauschen. Es sind offene Standards, die von den meisten professionellen Anbietern unterstützt werden. Da der Inhalt eines Systems jedoch stark von der Art der jeweiligen Segmentierung abhängt und die Definition des TMX-Formats breiten Interpretationsspielraum lässt, ist der Austausch in der Regel nicht verlustfrei.
Einzelnachweise
- Englische Übersetzung. In: TechDico. Abgerufen am 18. Juli 2019.