Index Sequential Access Method
Index Sequential Access Method (ISAM) ist eine von IBM Ende der 1960er Jahre entwickelte Zugriffsmethode für Datensätze einer Datei, die sowohl (sortiert) sequentiellen als auch wahlfreien (random) index-basierten Zugriff zulässt.
Eine Datei kann mehrere verschiedene Indizes haben. Jeder Index definiert eine unterschiedliche Reihenfolge der Datensätze, je nachdem, welche Informationen gesucht werden. Beispielsweise kann zu einer Kundendatei alphabetisch nach dem Nachnamen oder numerisch nach der Postleitzahl sortiert werden, sofern entsprechende Indizes existieren.
Die indexsequentielle Zugriffsmethode, die auch in Datenbanksystemen Verwendung findet, ermöglicht die Zugriffsgeschwindigkeit aufgabenabhängig zu optimieren. Seit den ersten Standards von COBOL um 1970 ist ISAM im File-Control-Paragraphen ansatzweise Teil des Standards der COBOL-Sprache. Eine sehr frühe Weiterentwicklung von ISAM, ebenfalls von IBM, aber nicht standardisiert, ist Virtual Storage Access Method (VSAM).
Speicherstruktur
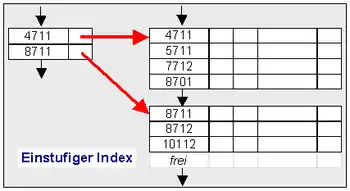
Die Datensätze sind in Blöcken oder Seiten zusammengefasst. Ein einfacher Index verweist auf den niedrigsten Schlüssel eines Datenblockes der Hauptdatei, die aufsteigend sortiert ist. Eine einfache, einstufige Indexdatei besteht aus Indexeinträgen, die auf Datenblöcke der Hauptdatei verweisen. In der Regel ist der Index mehrstufig, wobei die Indexebenen wiederum indexsequentiell organisiert sind.
- Suchen in einer ISAM-Datei: Suche den Schlüssel sequentiell in Indexdatei, solange bis er gefunden wird oder der Index größer als der gesuchte Schlüssel ist. Im zweiten Fall ist bei einem mehrstufigen Index nun bekannt, auf welcher Indexseite der gesuchte Schlüssel nur sein kann. Dort erfolgt der Suchprozess entsprechend solange, bis der Schlüssel gefunden oder nicht gefunden wurde.
- Einfügen: Zunächst Suchen, dann prüfen, ob der neue Satz auf die Seite passt. Falls ja sortiert einfügen, falls nein neuen Satz auf nächster Seite bzw. Überlaufseite einfügen und Indexseiten aktualisieren.
- Löschen: Zunächst Suchen, dann Satz als gelöscht kennzeichnen. Wenn es der erste Satz der Seite war oder die Seite nun leer ist, Indexseiten anpassen.
Ein Nachteil der ISAM-Dateiorganisation ist aus der Einfüge- und Löschoperation erkennbar. Die Hauptdatei und der Index sind statisch, neue Sätze werden häufig in Überlaufblöcken gespeichert und dadurch werden Suchoperationen langsamer. Stark wachsende oder sich verändernde Dateien müssen deshalb zeitaufwändig regelmäßig reorganisiert werden.
Methode 2
Die obige Methode wurde nicht sehr lange verwendet. Nachfolge war eine Methode, die auf eine Baum/Blattstruktur beruhte. Hierdurch war es möglich durch wenige Vergleiche festzustellen, wo sich der gesuchte Satz befand bzw. eingefügt werden sollte.
Aufbau des Schlüssels der Isam Datei (Index).
***************************************************************** * BLATT-NR * VATER * ***************************************************************** * * * BLATTINHALT (KEY) * * * ***************************************************************** * LINKER SOHN * RECHTER SOHN * *****************************************************************
Erster Eintrag bei Beginn der Datei (Wurzel).
Beispiel COBOL

Das nebenstehende Bild zeigt den File-Control Paragraphen für eine ISAM-Datei eines modernen COBOL-Compilers:
- SELECT ... ASSIGN TO: Zuordnung externer Dateiname zu internem Dateiname
- WITH COMPRESSION | WITH ENCRYPTION: optional mit Kompression bzw. Verschlüsselung
- ORGANIZATION IS INDEXED
- ACCESS MODE IS SEQUENTIAL | RANDOM | DYNAMIC: alternativ eine der drei Zugriffsmethoden. Sequentiell, über Index oder beides, d. h. mal über Index, ab diesem Startpunkt sequentiell und umgekehrt.
- RECORD KEY IS key-name [= seg-name ...] [ WITH [NO] DUPLICATES ]] ...: Der (primäre) Schlüssel kann aus mehreren Segmenten, d. h. einzelnen Feldern des Datensatzes bestehen, doppelte Schlüssel können erlaubt sein. Die Felder, von denen auch nur Teile als (Teil-)Index verwendet werden können, sind – wie in COBOL üblich – in der FILE DESCRIPTION zu definieren.
- ALTERNATER RECORD KEY IS ...: weitere Indexe können definiert werden.
- LOCK MODE IS EXCLUSIVE | AUTOMATIC | MANUAL ...:
- RESERVE {number} ALTERNATE AREA:
- COLLATING SEQUENCE IS alphabet-name:
ISAM heute
„ISAM-Dateien werden auch heute noch eingesetzt, nämlich immer dann, wenn sich der Einsatz einer relationalen Datenbank nicht wirklich lohnt (Datenmengen, Struktur, Performance, Kosten etc.).“ Es sind vermutlich immer noch mehr Daten in ISAM-Files gespeichert als in relationalen Datenbanken. Dabei handelt es sich nicht nur um Daten aus COBOL-Umgebungen, sondern speziell unter UNIX hat durch die Realisierung C-ISAM von Informix die indexsequentielle Zugriffsmethode beim Übergang vom Großrechner auf UNIX-Systeme eine weite Verbreitung gefunden. Aufbauend auf ISAM wurde außerdem das Datenbanksystem MyISAM entwickelt, das unter anderem im weit verbreiteten Datenbankmanagementsystem MySQL implementiert ist. Zudem basiert die Extensible Storage Engine (ESE, auch bekannt als Jet Blue) von Microsoft auf ISAM. Die ESE dient(e) z. B. als Datenbank für Microsoft Active Directory und Exchange.
Weblinks
- C-ISAM-Programmierhandbuch (englisch; PDF; 2,07 MB)
- Die MyISAM-Speicher-Engine als Teil von MySQL