Gewichtetes Votieren
Das gewichtete Voting (lateinisch Quorum Consensus) ist ein Verfahren, das die Datenintegrität bei replizierten Datenbanken gewährleisten soll. In Systemen, die aus einer Vielzahl von Einheiten bestehen, muss ein Weg gefunden werden, um im fehlerbehafteten Umfeld Daten von ihnen zu lesen und zu schreiben. Dabei soll auch Toleranz für Ausfälle der Einheiten gewährleistet werden, ohne die Konsistenz der Daten zu gefährden.
Verfahren
Gefordert wird Robustheit gegen Ausfälle von einzelnen Knoten (Netzwerkelement) und Konsistenz der Daten.
Das Quorum-Consensus-Verfahren kann dabei nicht nur mit dem Ausfall einzelner Knoten umgehen, sondern auch Konsistenz beim Zerfall des Netzwerkes in einzelne unabhängige Partitionen garantieren. Wichtig dabei ist, dass bei der Bildung mehrerer Partitionen des Netzwerkes, die durch Kommunikationsfehler entstehen können, nur eine Partition Änderungen an den Daten vornimmt.
Dazu wird mit einem Quorum gearbeitet. Knoten die zu einer Partition gehören dürfen nur operieren, wenn sie das Quorum besitzen. Dieses ist im einfachen Fall die Mehrheit (die Hälfte der Mitglieder + ein Knoten), kann aber auch über eine Gewichtung der einzelnen Mitglieder erreicht werden.
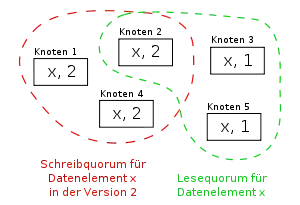
Jeder Knoten des Systems erhält so ein Gewicht und besteht ein sogenanntes Lesequorum RT und ein Schreibquorum WT, das bei einem Zugriff erfüllt werden muss. Zusätzlich wird eine Versionsnummer eingeführt, die beim Schreiben aktualisiert und beim Lesen ebenfalls ausgelesen wird.
Für das Setzen von RT und WT muss gelten:
- , nur bei Mehrheit wird geschrieben

- sowie
- , so wird beim Lesen mindestens eine aktuelle Version gefunden

Beim Schreiben eines Datums muss die Summe der Gewichte der beschriebenen Knoten das Schreibequorum erreichen. So wird nur bei Mehrheit aktualisiert und nur eine Partition kann Änderungen vornehmen, die Konsistenz der Datenbank bleibt erhalten. Die Knoten, die an dem Quorum teilnehmen werden aktualisiert, andere Knoten behalten ihren alten Wert.
Beim Lesen muss das Lesequorum erreicht werden, es werden also im Allgemeinen mehrere Knoten gelesen. Dabei können verschiedene Versionen gelesen werden, das Quorum garantiert allerdings, dass mindestens eine aktuelle Version darunter ist. Diese wird verwendet.
Eigenschaften
Die Wahl von RT und WT bietet Flexibilität. Hierdurch lässt sich in einem Datenbanksystem die Geschwindigkeit oder Priorität von Lesen und Schreiben einstellen (kleines RT für schnelles Lesen, kleines WT für schnelles Schreiben).
So kann durch mit Gewicht 1 für jeden Knoten und das Aktualisieren aller Knoten beim Schreiben und das Lesen nur eines Knotens modelliert werden (ROWA).


Anders als bei anderen Verfahren zur verteilten Replikation ist hier bei dem Ausfall eines Knotens nachträglich keine Wiederherstellung (Recovery) nötig. Der ausgefallene Knoten kommt zurück in den Verbund und enthält möglicherweise veraltete Daten. Durch das Lesequorum ist aber sichergestellt, dass jeweils die aktuelle Version gefunden wird.
Beispiel
Gegeben seien 5 Knoten mit je einem Gewicht von 1. Setzt man RT = 1 und WT = 5, so bedeutet das, dass für eine Leseoperation nur ein Knoten zustimmen muss. Für einen Schreibzugriff muss man hingegen auf alle Ressourcen schreiben. Dieses System wäre allerdings nicht ausfallsicher.
Man könnte hingegen auch WT = 4 setzen und RT = 2; hier wäre Schreiben beim Ausfall eines Knotens noch möglich.
Nachteile des Verfahrens
Das Quorum-Consensus-Verfahren generiert eine hohe Last beim Lesen von Daten, da mehrere Knoten gelesen werden müssen, um das Lesequorum zu erreichen.
Ebenso sind eine große Menge von Replikationen nötig um den Ausfall weniger Komponenten zu verkraften (z. B. 3 Knoten um den Ausfall eines Knotens zu überstehen).
Verbesserung
Durch den Missing-Writes-Algorithmus kann eine ROWA-Strategie verwendet werden, solange es zu keinen Ausfällen kommt. So wird jeder Knoten bei einer Änderung aktualisiert. Damit kann schnelles Lesen (nur von einem Knoten) erreicht werden. Erst bei einem Ausfall wird auf Quorum Consensus umgestellt um die ausgefallenen Knoten zu kompensieren.
Literatur
- Kemper, Alfons und André Eickler: Datenbanksysteme - Eine Einführung. 7. Auflage. Oldenbourg Verlag München, 2009, ISBN 978-3-486-59018-0.
Weblinks
- Mehrrechner-Datenbanksysteme – Elektronisches Buch auf der Internetseite der Abteilung Datenbanken am Institut für Informatik (Universität Leipzig)