GLUE
GLUE ist ein System zur Ermittlung von Ontologie-Mappings, welches hierfür Maschinen-Lerntechniken einsetzt.
Mithilfe des Naive-Bayes-Verfahrens wird die Verteilung der Instanzen der zu matchenden Ontologien geschätzt. Hieraus lassen sich Ähnlichkeitswerte für alle Konzepte ableiten. Die Informationen über die Struktur der Ontologie werden daraufhin genutzt, um die ermittelten Ähnlichkeitswerte nach oben oder unten zu korrigieren.
Herkunft
Das System basiert auf der Beschreibung in einem wissenschaftlichen Artikel[1]. Der Artikel entstand in Kooperation zwischen Wissenschaftlern der University of Illinois at Urbana-Champaign (AnHai Doan, Robin Dhamankar) sowie der University of Washington (Pedro Domingos, Jayant Madhavan, Alon Halevy). Es werden einige Ideen des Vorgänger-Systems LSD[2] (Learning Source Descriptions) wieder aufgegriffen.
Ontology Matching
Das Ziel von GLUE ist das Finden des besten Mappings zweier Ontologien. Betrachtet werden hier eine Quell- und eine Ziel-Ontologie. Beide Ontologien bestehen aus Konzepten, die Attribute besitzen können. Jedes Konzept kann konkrete Instanzen (Exemplare) haben, die jeweils einen eigenen Namen und konkrete Attributwerte haben. Konzepte können Kind-Konzepte von anderen Konzepten sein und dadurch beispielsweise deren Attribute erben.
Gesucht ist eine Abbildung der Konzepte der Quell-Ontologie auf die Konzepte der Ziel-Ontologie. Hierfür werden die Informationen über die Struktur der Ontologie sowie die konkreten Instanzen der einzelnen Konzepte herangezogen.
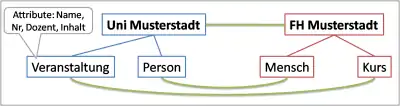
Beispiel
Das Bild zeigt zwei Beispiel-Ontologien aus der Universitäts-Domäne. Die Ontologie Uni Musterstadt hat ein gleichnamiges Wurzel-Konzept, welches zwei Kind-Konzepte Veranstaltung und Person besitzt. Das Konzept Veranstaltung hat die Attribute Name, Nr, Dozent und Inhalt. Eine Instanz des Konzepts Veranstaltung könnte beispielsweise die folgenden Eigenschaften aufweisen:
- Instanzname: Schema Matching WS 07/08
- Konzept: Veranstaltung
- Attribute:
- Name: Schema Matching
- Nr: 01 L 300
- Dozent: Prof. Dr. Felix Naumann
- Inhalt: Ein Seminar zum Thema Schema Matching.
Die Aufgabe von GLUE ist es nun, alle im Bild dargestellten grünen Beziehungen der Konzepte der Ontologien zu finden. Dazu gehören etwa die Abbildung des Konzepts Veranstaltung auf Kurs sowie Person auf Mensch.
Ablauf
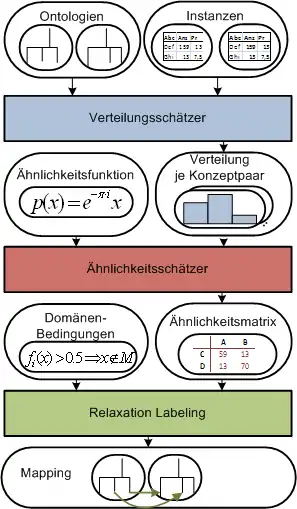
Die Verarbeitung in GLUE besteht aus drei Phasen.
1. Verteilungsschätzung
Zunächst werden alle möglichen Paare von Konzepten gebildet, die jeweils ein Konzept der zu prüfenden Ontologien enthalten. Für jedes Paar wird dann die Wahrscheinlichkeitsverteilung geschätzt. Die Frage, die hierbei für jedes Konzeptpaar zu beantworten ist, lässt sich in etwa so formulieren: Wenn aus der Obermenge aller Elemente der beiden Ontologien zufällig eines herausgegriffen wird, wie hoch ist die Wahrscheinlichkeit, dass das Element zu genau diesen beiden Konzepten gehört?
GLUE nutzt hierfür das Naive Bayes-Verfahren als Lerntechnik. Mithilfe der Informationen über die Elemente eines Konzepts kann beurteilt werden, wie wahrscheinlich es ist, dass ein beliebiges anderes Element auch zu diesem Konzept gehört.
2. Ähnlichkeitsschätzung
Für jedes Konzeptpaar wird dann ein nutzerdefiniertes Ähnlichkeitsmaß auf die berechneten Wahrscheinlichkeitswerte angewendet. Das Ergebnis ist eine Ähnlichkeitsmatrix, die die Ähnlichkeitswerte jedes Konzeptpaars beinhaltet.
3. Relaxation Labeling
Zuletzt werden die Ähnlichkeitsmatrix sowie zusätzliche Bedingungen und Heuristiken verwendet, um das bestmögliche Mapping der beiden Ontologien zu bestimmen.
Erst an dieser Stelle nutzt GLUE die Informationen über die Struktur der Ontologie. Das System betrachtet beispielsweise die berechneten Ähnlichkeitswerte der Eltern-Konzepte, der Geschwister-Konzepte und der Kind-Konzepte eines Konzepts. Die Ähnlichkeitswerte dieses Konzepts können dann an die Werte der Nachbar-Konzepte angepasst, also gesenkt oder erhöht werden.
Das Ergebnis ist auch hier wieder eine Ähnlichkeitsmatrix. Mithilfe von globalen Matching-Verfahren, die nicht von GLUE vorgeschrieben werden, kann daraus ein mögliches Mapping abgeleitet werden.
Einzelnachweise
- A. Doan, J. Madhavan, R. Dhamankar, P. Domingos, and A. Y. Halevy. Learning to match ontologies on the semantic web. VLDB Journal, 12(4):303–319, 2003
- A. Doan, P. Domingos, and A. Y. Levy. Learning source description for data integration. In D. Suciu and G. Vossen, editors, Proceedings of the Third International Workshop on the Web and Databases, WebDB 2000, Adam’s Mark Hotel, Dallas, Texas, USA, May 18-19, 2000, in conjunction with ACM PODS/SIGMOD 2000, pages 81–86, 2000