Cross-interleaved Reed-Solomon Code
Cross-interleaved Reed-Solomon Codes (CIRC) dienen der Fehlererkennung und Fehlerkorrektur bei CDs.
Anforderungen
Die Anforderungen an CIRC kann man folgendermaßen zusammenfassen:
Es besteht eine hohe Einzelfehlerkorrekturrate (oder Zufallsfehlerkorrekturrate), die durch unsauber abgebildete Bits oder Produktionsfehler ausgelöst werden. Des Weiteren gibt es eine hohe Flächenfehlerkorrekturrate, die durch Staubkörner oder Kratzer auf der CD Oberfläche ausgelöst werden. Diese sind für diese Art von Fehler verantwortlich. Außerdem wird eine einfache Dekodierer-Strategie benötigt. Zu guter Letzt ist noch anzuführen, dass ein weiteres Kriterium geringe Redundanzen sind.
Fehler auf der CD sind Kombinationen von Zufallsfehlern und Flächenfehlern. Um dies zu bewältigen, kommt ein Produktcode mit zusätzlich mehrfachem Interleaving zum Einsatz.
Verwendete Codes
Auf der CD werden zwei Codes (32,28,5) und verwendet, die aus einem (255,251,5) RS-Code durch Verkürzung um 227 bzw. 218 Stellen entstehen.


Cross Interleaving
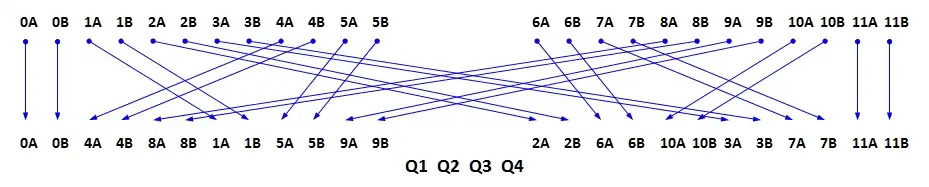
[1] Der CIRC bearbeitet Blöcke von 24 Byte, die in weiterer Folge als Frame 1 (F1) bezeichnet werden. Im ersten Schritt wird ein Block mit Hilfe des sogenannten -Scramblers folgendermaßen verzögert: Der F1-Block wird in zwei mal 12 Byte unterteilt und die einzelnen A/B-Paare um jeweils 2 Blöcke verzögert. Die vier freibleibenden Blöcke werden im nächsten Schritt durch den -Encoder mit Q-Paritätssymbolen (Q1,Q2,Q3,Q4) belegt. Durch das Ablegen der Paritätssymbole in der Mitte des Blocks vergrößert sich der Abstand zwischen ursprünglich aufeinander folgenden Bytes weiter. Dieses Zwischenergebnis wird oft F2-Frame genannt. Diese erste Interleavingstufe dient im späteren Dekodieren der Korrektur von Zufallsfehlern und der Markierung von Flächenfehlern. Die Unterscheidung zwischen A- und B-Blöcken soll zeigen, dass es sich jeweils um Werte der beiden Audiokanäle ``links und ``rechts handelt.

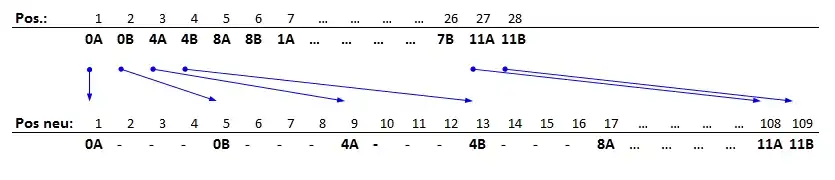
Der -Scrambler empfängt ein 28-Byte-F2-Wort, wobei jedes einzelne Byte um einen ganzzahligen Wert von 4 verzögert wird. Das ursprüngliche 28-Byte-Wort wird also über 109 Byte zu einem F3a-Wort verteilt.
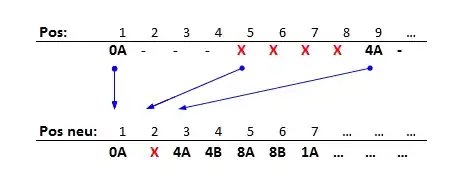
Sollte beim Dekodieren zum Beispiel ein Flächenfehler der Länge 4 in einem F3a-Wort erkannt werden, wird dieser durch den -Unscrambler auf vier F2-Frames verteilt. Dadurch kann in weiterer Folge der ursprüngliche Flächenfehler als vier Einzelfehler behandelt werden.
Der -Encoder empfängt ein 28-Byte-Wort, welches aus 28 verschiedenen F2-Frames gebildet wird, und erzeugt weitere 4 Bytes mit P-Parität. Eine letzte Verzögerungsstufe verarbeitet zwei F3a-Frames, indem die ungeraden Bytes um einen Betrag von einem Byte verzögert werden. Dadurch können Einzelfehler nicht mehr als ein Symbol pro Wort beeinträchtigen, auch wenn zwei aufeinander folgende Symbole eines Blocks fehlerhaft sind. Aus zwei F3a-Frames entstehen somit zwei F3-Frames. Dieses letzte Interleaving ermöglicht es, relativ kleine Flächenfehler besser korrigieren zu können. Durch diese Verzögerungsstufe entsteht der Nachteil, dass in Kombination mit Taktschwierigkeiten beim Auslesen ein Null-Wort entstehen kann. Um dies zu verhindern, werden die P- und Q-Paritätssymbole invertiert.
Decoder
Da CIRC-Decoder nicht standardisiert sind, gibt es mehrere Möglichkeiten einen Decoder zu implementieren. bezeichnet in weiterer Folge die Anzahl der Auslöschungsflags, die als Input übergeben werden.

C1-A-Decoder
IF Syndrom für ein oder null Fehler THEN bearbeite ein oder kein Symbol entsprechend ELSE setze Auslöschungsflags für das gesamte empfangene Wort ENDIF
C2-A-Decoder
IF Syndrom für ein oder null Fehler THEN bearbeite ein oder kein Symbol entsprechend ELSE IF f > 2 THEN kopiere C2 Auslöschungsflags von den C1 Auslöschungsflags ELSE IF f = 2 THEN versuche 2 Auslöschungen zu korrigieren ELSE IF f < 2 OR 2 Auslöschungen korrigieren scheitert THEN setze Auslöschungsflags für das gesamte empfangene Wort ENDIF
C1-B-Decoder (bessere Strategie)
IF Syndrom für ein oder null Fehler THEN bearbeite ein oder kein Symbol entsprechend ELSE IF Syndrom für 2 Fehler THEN bearbeite 2 Symbole entsprechend setze Auslöschungsflags für das gesamte empfangene Wort ELSE setze Auslöschungsflags für das gesamte empfangene Wort ENDIF
C2-B-Decoder (bessere Strategie)
IF Syndrom für ein oder null Fehler THEN
bearbeite ein oder kein Symbol entsprechend
ELSE IF f <= 4 THEN
IF Syndrom für 2 Fehler AND v = 2 THEN
bearbeite 2 Symbole entsprechend
ELSE IF Syndrom für 1 Fehler AND f <= 2 THEN
bearbeite 3 Symbole entsprechend
ELSE IF Syndrom für 2 Fehler AND ((v = 1 AND f <= 3) OR (v=0 AND f <= 2)) OR (f <= 2 AND NOT Syndrom für 2 Fehler) THEN
setze Auslöschungsflags für das gesamte empfangene Wort
ELSE
kopiere C2 Auslöschungsflags von C1 Auslöschungsflags
ENDIF
ELSE
kopiere C2 Auslöschungsflags von C1 Auslöschungsflags
ENDIF
Beispiel Decodieren
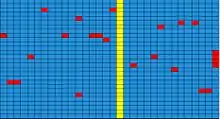
Angenommen die Matrix enthält 18 Spalten mit je einem Fehler, eine Spalte mit zwei Fehlern, eine weitere Spalte mit vier Fehlern und 11 korrekte Spalten. Außerdem wurde bereits eine komplette Spalte mit Auslöschungsflags versehen, da die Hardware diesen Teil nicht erkennen konnte.
Die Spalten wurden mit einem (28,24,5) - Code codiert, das heißt, er kann alle 1-fach- und 2-fach-Fehler korrigieren. Der C1-A-Decoder nutzt im Gegensatz zum C1-B-Decoder diese Möglichkeit nicht optimal. Verwendet man den C1-B-Decoder werden die Spalten mit Einfach- und Zweifachfehlern korrigiert. Die Spalte mit dem Zweifachfehler wird zusätzlich mit Auslöschungsflags versehen. Bei der Spalte mit vier Fehlern können zwei Fälle auftreten. Zum einen kann dies erkannt werden und es werden Auslöschungsflags gesetzt oder es wird falsch korrigiert und ein weiterer Fehler kommt dazu.


Die Zeilen wurden mit einem (32,28,5)-Code codiert. Sollte der C1-B-Decoder die Spalte mit vier Fehlern falsch korrigieren, stößt der C2-B-Decoder auf fünf falsche Zeilen mit je einem Fehler und zwei Auslöschungen. Sollten die vier Fehler erkannt werden muss der C2-B-Decoder vier falsche Zeilen mit je drei Auslöschungen korrigieren. In beiden Fällen kann der C2-B-Decoder die Fehler beziehungsweise die Auslöschungen richtig korrigieren. Der C2-A-Decoder könnte diese Fehler nicht korrigieren.
A priori kann der Code als Linearcode mit alle 12-fach Fehler oder 24 Auslöschungen korrigieren. Durch das Zusammenspiel von Zeilen- und Spaltenkorrektur werden in diesem Beispiel 24 Fehler und 28 Auslöschungen korrigiert. Die Korrekturkapazität wird also mehr als verdreifacht.


Siehe auch
Einzelnachweise
- K. Pohlmann. Compact Disc Handbuch. IWT, 1 edition, 1994. ISBN 3-88322-500-2.