ConedaKOR
| ConedaKOR | |
|---|---|
| Basisdaten | |
| Entwickler | Moritz Schepp, Thorsten Wübbena |
| Erscheinungsjahr | 2009 |
| Aktuelle Version | 4.1.0 (07. Dezember 2021) |
| Kategorie | Bilderverwaltung |
| Lizenz | GNU Affero General Public License |
| GitHub | |
Das Werkzeug
ConedaKOR ist eine quelloffene wissenschaftliche Forschungssoftware, die seit 2009 im geisteswissenschaftlichen Forschungskontext eingesetzt und konstant durch die community weiterentwickelt wird. ConedaKOR leistet die Archivierung, Verwaltung und Recherche von Bild- und Metadaten auf einer gemeinsamen webbasierten Oberfläche. In der bildorientierten Forschung – insbesondere der Kunstgeschichte und der Archäologie – sind digitale Repräsentanten zentrale Arbeitsmittel, um den meist analogen Untersuchungsgegenstand in Forschung und Lehre verfügbar zu machen. Für die Bereitstellung dieser Forschungsdaten wurde das Datenbanksystem ConedaKOR entwickelt, das am Kunstgeschichtlichen Institut in Frankfurt am Main seinen Ursprung hat und wo bis heute die größte ConedaKOR-Instanz im Hinblick auf verwaltete Nutzer und Entitäten (>300.000) betrieben wird. Inzwischen wird ConedaKOR in diversen Hochschulen und Forschungsinstitutionen eingesetzt, so u. a. an den Universitäten in Bochum, Freiburg und Saarbrücken, dem Deutschen Forum für Kunstgeschichte Paris sowie dem Leibniz-Institut für Europäische Geschichte. Als „Software as a Service“-Lösung wird ConedaKOR auch über DARIAH-DE angeboten und dient so seit einigen Jahren dem Akademievorhaben „Textdatenbank und Wörterbuch des Klassischen Maya“ zur Verwaltung seines umfangreichen Bildkonvoluts.
Backend
ConedaKOR setzt auf ein klassisches relationales Datenbanksystem als Storage-Backend, wobei die Ablage der Medien im Dateisystem erfolgt. Die Web-Applikation selbst läuft auf der Basis von Ruby on Rails und Riot.js. Das Konzept „Graph“ wird in ConedaKOR in erster Linie als ontologisches Ordnungssystem verstanden und fungiert als Benutzerschnittstelle, die nicht nur Daten abfragebasiert anzeigt, sondern die Nutzer auch ermächtigt, direkt in die Modellierung einzugreifen. Die Erstellung der Graphstruktur erfolgt über ein Web-Interface, welches auch die Eingabe und die Anzeige umsetzt, sodass für die einzelnen Arbeitsschritte die gleiche Oberfläche genutzt werden kann.
Schnittstellen
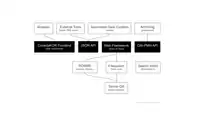
ConedaKOR folgt einem „API-First-Ansatz“ und stellt Programmierschnittstellen zur Verfügung, welche durch verschiedene „Verbraucher“ genutzt werden können. So wird u. a. auch die systemeigene Weboberfläche über eine API bedient, zudem ergeben sich weitere Anwendungen, die das Datenbanksystem als schnittstellenstarkes Werkzeug im Backend in Erscheinung treten lassen. Sei es mit einem spezifisch gestalteten Frontend oder sei es als Repositorium, welches Daten in bestehende Umgebungen einfließen lässt (so z. B. umgesetzt im Vorhaben Sandrart.net[1][2]). Die REST(JSON)-API wird kontinuierlich erweitert und dient den Anfragen nach einzelnen bzw. einer Reihe von Datensätzen. Zudem bietet ConedaKOR insgesamt vier Endpunkte für das Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) an, die jeweils die Inhalte von Entitätstypen, Entitäten, Verknüpfungen und Verknüpfungstypen abrufbar machen. Dieser Ansatz ermöglicht die Reproduktion oder Zusammenführung der Daten, also etwa für Backups oder Hub-Instanzen. Aber auch Harvester werden hier bedient, womit u. a. ein Wunsch der community umgesetzt wurde, um Daten „on-the-fly“ mit „prometheus – Das verteilte digitale Bildarchiv für Forschung und Lehre“ synchronisieren zu können.
Technische Anforderungen
Serverseitig
- UNIX-kompatibles Betriebssystem (Linux, Mac OS X, AIX, Solaris etc.)
- MySQL / MariaDB
- ImageMagick (für Bilddateihandling)
- ffmpeg (für Videodateihandling)
- Ruby
Clientseitig
- aktueller Browser (Firefox, Chromium, Safari, Edge)
Einzelnachweise
- Sandrart.net x ConedaKOR, auf coneda.net, abgerufen am 26. Dezember 2021
- ConedaKOR-as-a-Service. Über Kontext, Komplexität und Komplikationen, auf dhlab.hypotheses.org, abgerufen am 26. Dezember 2021