Adaptive Computing
Adaptive Computing ist ein Konzept zur flexiblen Zuordnung von Ressourcen (Prozessor, Hauptspeicher, Sekundärspeicher) an Dienste und Applikationen in Rechenzentrumsumgebungen. Ziel ist es, vorhandene Hardware-Ressourcen bedarfsgerecht einzusetzen und auf diese Weise Kosten zu senken. Auch das Management von IT-Infrastrukturen soll sich auf diese Weise vereinfachen.
Von statischen Client-Server-Strukturen zu Adaptive Computing
Traditionelle IT-Infrastruktur, Nachteile
Größere Unternehmen betreiben in der Regel mehrere Server, auf denen unterschiedliche Systeme die betrieblichen Prozesse des Unternehmens unterstützen. Dazu gehören ERP-Systeme zur Integration von Produktion, Finanzwesen etc., Planungssystem oder Data-Warehouse-Systeme. Im Umfeld des Application Service Providing, in großen oder global agierenden Unternehmen oder in Zusammenhang von Entwicklungsinfrastrukturen werden oft mehr als jeweils ein System betrieben.
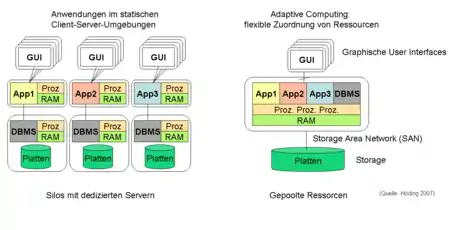
Im Allgemeinen ist dabei ein System auf einem oder mehreren dedizierten Server-Rechnern installiert. Dadurch entstehen Installationen aus einer Vielzahl von heterogenen Server-Rechnern. Ursachen der Heterogenität sind
- Unterschiedlichen Anforderungen der Anwendungen: ERP-System vs Data-Warehouse-System
- Art der Anwendung: Produktives System vs. Entwicklungssystem
- Historische Ursachen wie Hardwareentwicklung, Einkauf von Hardware
Dies erschwert den Systembetrieb.
Ein weiterer Nachteil statischer Architekturen liegt in der geringen Anpassungsfähigkeit z. B. bei Lastspitzen. Ein System muss im Sinne der Benutzbarkeit so ausgelegt sein, dass es auch in Hochlastzeiten ein akzeptables Antwortzeitverhalten hat. Selten werden Systeme jedoch über den gesamten Tag kontinuierlich stark genutzt. In betriebsschwächeren Zeiten liegen somit Ressourcen brach.
Übergang zum Adaptive Computing
Beim Adaptive Computing werden nun die vorhandenen Ressourcen für eine gemeinsame Nutzung konfiguriert. Der erste Schritt besteht darin, dedizierte Hardware für die Ressourcenarten anzuschaffen. Der zweite Schritt bildet Pools der Ressourcen. Im dritten Schritt werden Applikationen und Szenarien definiert, die diese Pools bedarfsgerecht nutzen oder zuordnen.
Statt vieler Server mit jeweils Prozessoren, Hauptspeicher, Sekundärspeicher und Netzwerk hat man nun
- einen integrierten Server mit einer großen Anzahl von Prozessoren und
- einem großen Hauptspeicher
- konfigurierbare Netzwerkstrukturen, darunter Storage Area Networks
- externe Speichersysteme, Disk-Arrays
Während externe Speichersysteme bereits in Zusammenhang mit eher statischen Client-Server-Installationen zu Einsatz kamen, stellt die flexible Zuordnung von Prozessor und Hauptspeicher eine entscheidende Neuerung dar.
Vorteil: Einsparung von Ressourcen bei Lastspitzen
Die Benutzung von Anwendungssystemen erfolgt nicht gleichmäßig. Typische Lastspitzen ergeben sich z. B. bei E-Commerce-Systemen (B2C) in den Abendstunden oder im betrieblichen Umfeld infolge der Systemanmeldung beim Arbeitsbeginn.
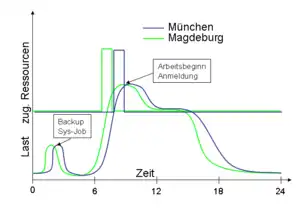
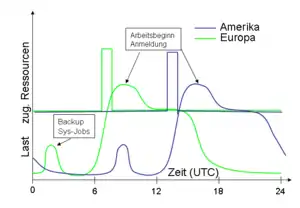
Letzterer Zeitraum ist oft unterschiedlich, nicht nur im globalen Kontext (Europa, Amerika), sondern auch im regionalen Kontext. So ist der Arbeitsbeginn trotz gleicher geographischer Länge in Sachsen-Anhalt ca. eine Stunde früher als in München. Diese Tatsache auszunutzen erlaubt nun Adaptive Computing. Entsprechend gefundener oder definierter Benutzungsmuster wird nun
- von 7 bis 8 Uhr ein größerer Teil der Ressourcen dem in Sachsen-Anhalt genutzten System zugeordnet und
- von 8 bis 9 Uhr wird ein großer Teil der Ressourcen München zugeordnet.
- Ab 9 Uhr sind die Ressourcen gleich verteilt.
Damit können kurzfristige Lastspitzen abgefangen werden. Dies ist in traditionellen Infrastrukturen nur durch eine geschickte und langfristig geplante Verteilung von Systemen auf Ressourcen möglich.
Vorteil: Vereinfachung des Systemmanagements
Auch längerfristige Anforderungsänderungen können durch Adaptive Computing gut abgedeckt werden mit dem Vorteil kürzerer Realisierungszeiten. (Unter „längerfristig“ soll in diesem Zusammenhang Tage statt Minuten oder Stunden bei Lastspitzen verstanden werden.)
Wird ein zusätzliches Anwendungssystem installiert, so ist eine lang dauernde Hardwarebeschaffung nicht zwingend erforderlich. Dies ist besonders interessant für Evaluationsprojekte. Beim Adaptive Computing werden im Rahmen der vorhandenen Architektur flexibel Ressourcen zugeordnet. Die bereits laufenden Anwendungen werden marginal beeinflusst.
Literatur
- Ian Parmee: Adaptive Computing in Design and Manufacture V. Springer Verlag, London 2002, ISBN 978-1-85233-605-9.
- Ian C. Parmee: Evolutionary and Adaptive Computing in Engineering Design. Springer Verlag, London 2001, ISBN 978-1-4471-1061-3.
- Nadia Nedjah, Chao Wang (Hrsg.): Reconfigurable and Adaptive Computing. Theory and Applications, Taylor & Francis Group LTC, 2016, ISBN 978-1-4987-3176-8.
- Anupam Shukla, Ritu Tiwari, Rahul Kala: Towards Hybrid and Adaptive Computing. A Perspective, Springer Verlag, Berlin / Heidelberg 2010, ISBN 978-3-642-14343-4.
- Ran Chen: Intelligent Computing and Information Science. Springer Verlag, Berlin / Heidelberg 2011, ISBN 978-3-642-18128-3.
Weblinks
- An Effective Technique for Adaptive Computing (abgerufen am 27. Juli 2017)